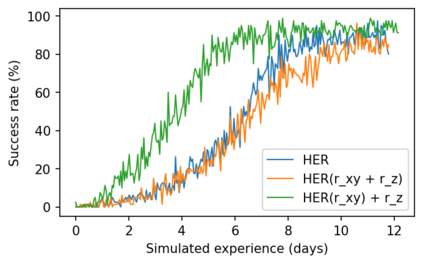
This paper details our winning submission to Phase 1 of the 2021 Real Robot Challenge, a challenge in which a three fingered robot must carry a cube along specified goal trajectories. To solve Phase 1, we use a pure reinforcement learning approach which requires minimal expert knowledge of the robotic system or of robotic grasping in general. A sparse goal-based reward is employed in conjunction with Hindsight Experience Replay to teach the control policy to move the cube to the desired x and y coordinates. Simultaneously, a dense distance-based reward is employed to teach the policy to lift the cube to the desired z coordinate. The policy is trained in simulation with domain randomization before being transferred to the real robot for evaluation. Although performance tends to worsen after this transfer, our best trained policy can successfully lift the real cube along goal trajectories via the use of an effective pinching grasp. Our approach outperforms all other submissions, including those leveraging more traditional robotic control techniques, and is the first learning-based approach to solve this challenge.
翻译:本文详细介绍了我们向2021年真正的机器人挑战第一阶段的获胜申请, 3个手指机器人必须随特定目标轨迹携带立方体的挑战。 为了解决第一阶段, 我们使用纯强化学习方法, 需要最起码的机器人系统或一般机器人捕捉的专业知识。 与Hindsight 经验重现一起使用一个稀少的基于目标的奖励来教授控制政策, 将立方体移动到理想的x 和 y 坐标。 同时, 使用密集的远程奖励来教授将立方体提升到理想的 z 坐标的政策。 该政策在传输到真正的机器人之前先用域随机化进行模拟培训。 尽管在转移到真正的机器人进行评估之前,我们经过最佳培训的政策往往会恶化, 但是通过有效抓抓取, 我们的最佳政策可以成功地沿目标轨迹提升真正的立方体。 我们的方法超越了所有其他的提交方法, 包括利用更传统的机器人控制技术, 并且是第一个基于学习的方法来应对这一挑战。