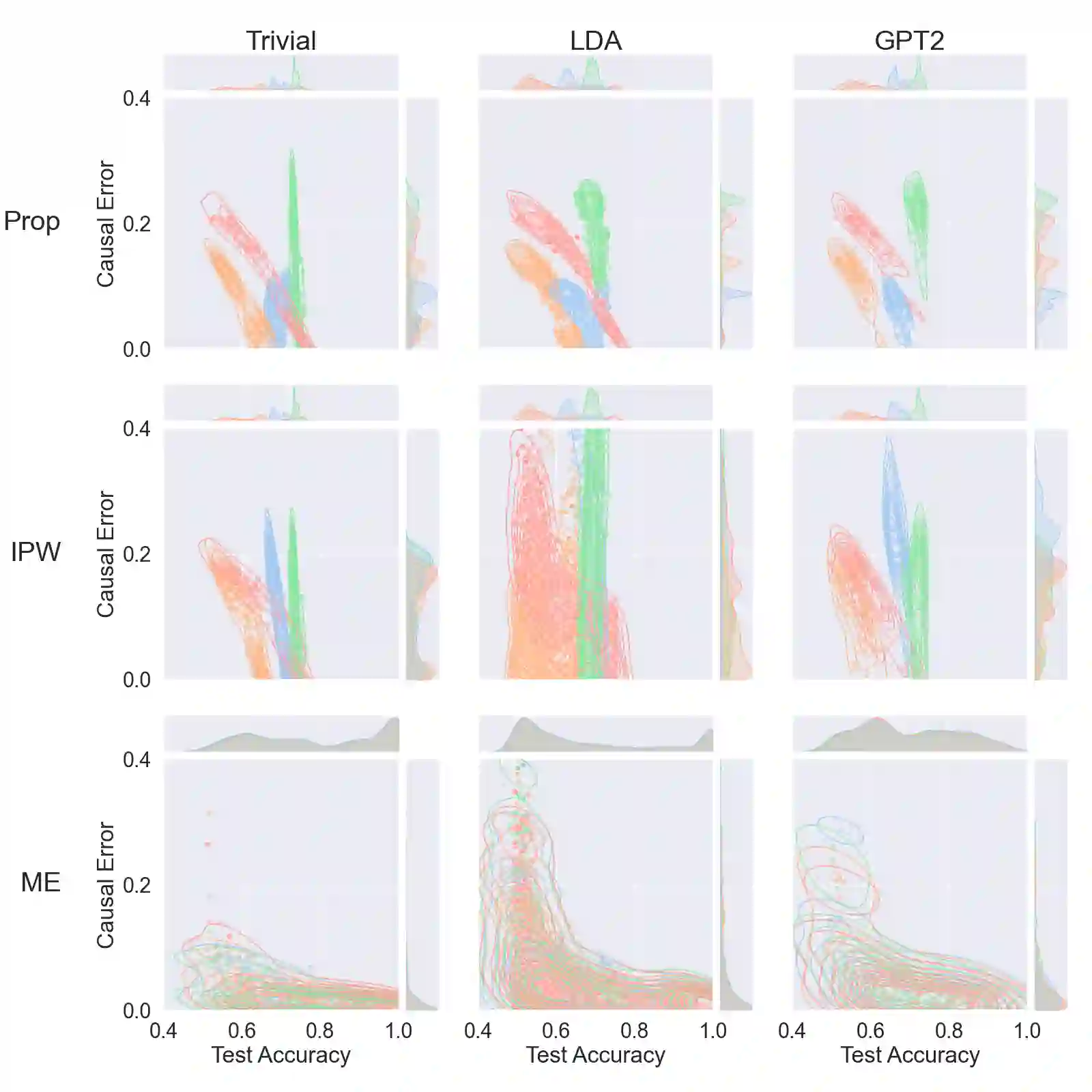
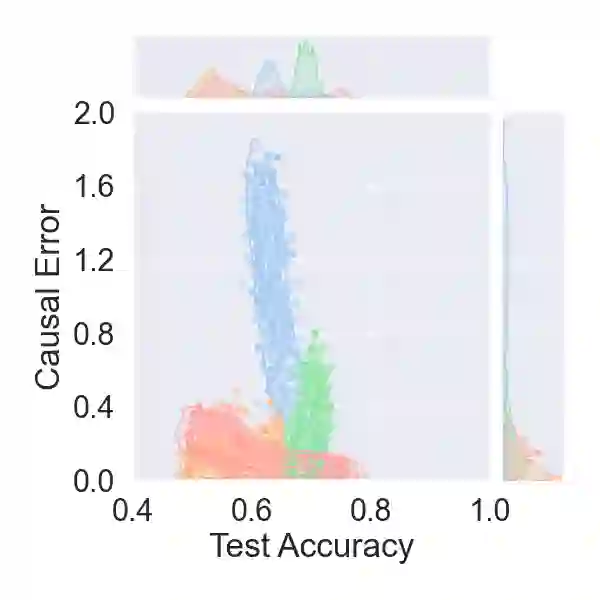
Drawing causal conclusions from observational data requires making assumptions about the true data-generating process. Causal inference research typically considers low-dimensional data, such as categorical or numerical fields in structured medical records. High-dimensional and unstructured data such as natural language complicates the evaluation of causal inference methods; such evaluations rely on synthetic datasets with known causal effects. Models for natural language generation have been widely studied and perform well empirically. However, existing methods not immediately applicable to producing synthetic datasets for causal evaluations, as they do not allow for quantifying a causal effect on the text itself. In this work, we develop a framework for adapting existing generation models to produce synthetic text datasets with known causal effects. We use this framework to perform an empirical comparison of four recently-proposed methods for estimating causal effects from text data. We release our code and synthetic datasets.
翻译:从观察数据中得出因果结论要求假设真正的数据产生过程。 因果推断研究通常考虑低维数据,如结构化医疗记录中的绝对或数字领域。自然语言等高维和非结构化数据使因果推断方法的评估复杂化;这种评价依靠已知因果效应的合成数据集;自然语言生成模型已经进行了广泛研究,在经验上运作良好。然而,现有方法不能立即适用于为因果评估制作合成数据集,因为它们无法量化对文本本身的因果影响。我们在此工作中制定了调整现有生成模型以生成已知因果效应的合成文本数据集的框架。我们利用这一框架对最近提出的四种估算文本数据因果效应的方法进行经验比较。我们发布了我们的代码和合成数据集。