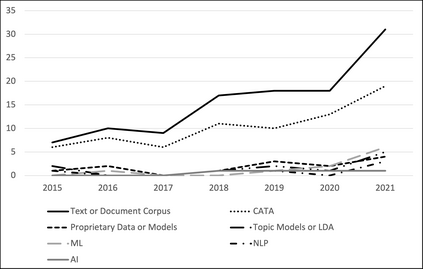
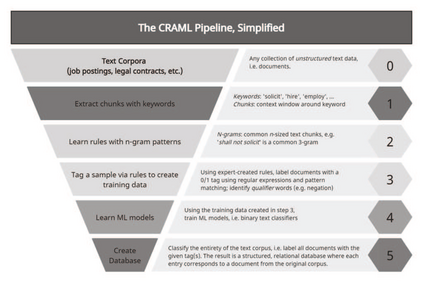
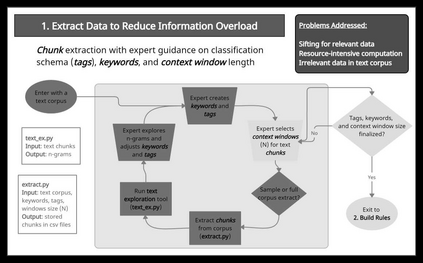
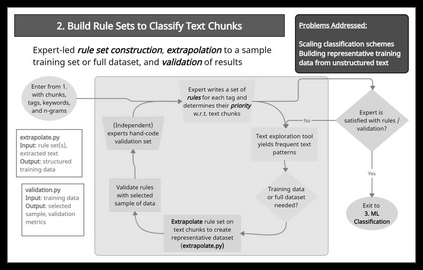
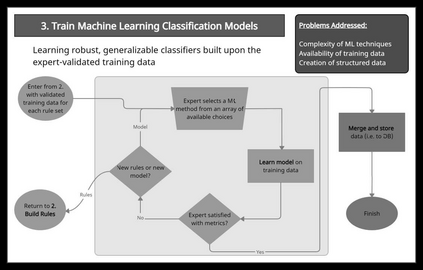
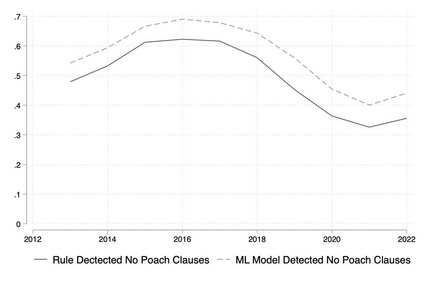
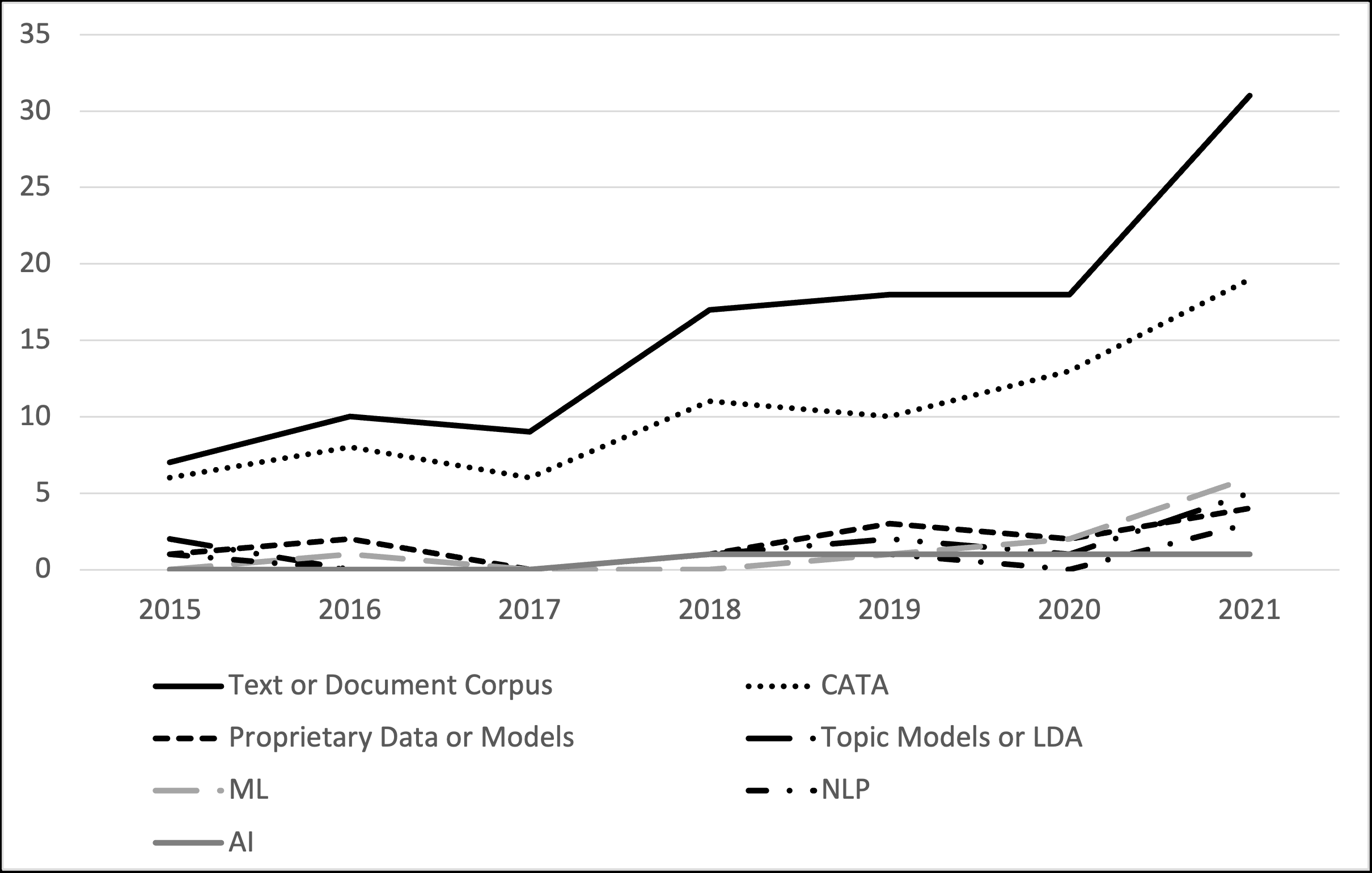
We describe a method and new no-code software tools enabling domain experts to build custom structured, labeled datasets from the unstructured text of documents and build niche machine learning text classification models traceable to expert-written rules. The Context Rule Assisted Machine Learning (CRAML) method allows accurate and reproducible labeling of massive volumes of unstructured text. CRAML enables domain experts to access uncommon constructs buried within a document corpus, and avoids limitations of current computational approaches that often lack context, transparency, and interpetability. In this research methods paper, we present three use cases for CRAML: we analyze recent management literature that draws from text data, describe and release new machine learning models from an analysis of proprietary job advertisement text, and present findings of social and economic interest from a public corpus of franchise documents. CRAML produces document-level coded tabular datasets that can be used for quantitative academic research, and allows qualitative researchers to scale niche classification schemes over massive text data. CRAML is a low-resource, flexible, and scalable methodology for building training data for supervised ML. We make available as open-source resources: the software, job advertisement text classifiers, a novel corpus of franchise documents, and a fully replicable start-to-finish trained example in the context of no poach clauses.
翻译:我们描述了一种方法和新的无编码软件工具,使域专家能够从文件的无结构文本中建立自定制结构化的、贴标签的数据集,并建立可追溯到专家规则的独特的机器学习文本分类模型。背景规则辅助机器学习(CRAML)方法允许对大量无结构文本进行准确和可复制的标签。CRAML使域专家能够进入文件文体中埋藏的不寻常的建筑,避免当前常常缺乏背景、透明度和互连性的计算方法的局限性。在本研究方法文件中,我们为CRAML提供了三种使用案例:我们分析了从文本数据中提取的最近管理文献,描述并发布了从专有职业广告文本分析中提取的新机器学习模型,并介绍了从公共文献中获取的社会和经济利益调查结果。CRAML制作了文件级编码表格数据集,可用于定量学术研究,并使定性研究人员能够将特有分类方法比照大量文本数据。CRAML是一种低资源、灵活和可缩的方法,用于为受监督的ML建立培训数据。我们把经过全面升级的版本用作公开的版本。我们把一个经过培训的模板的软件。我们可以完全复制了。