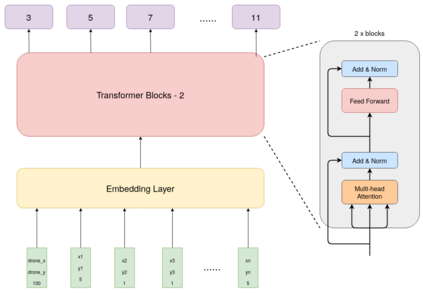
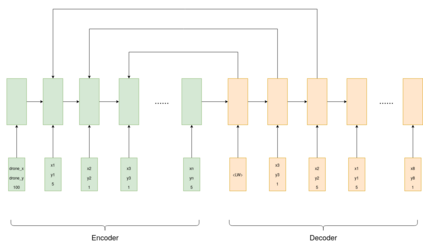
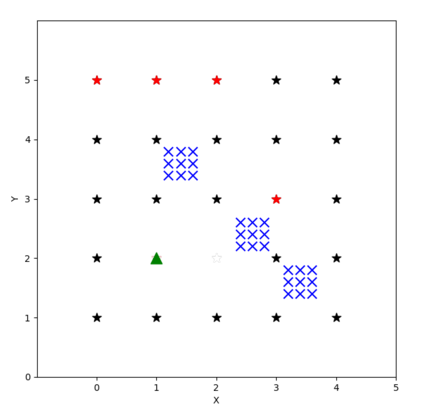
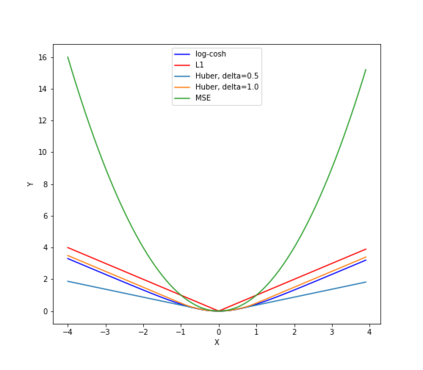
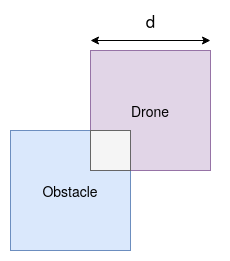
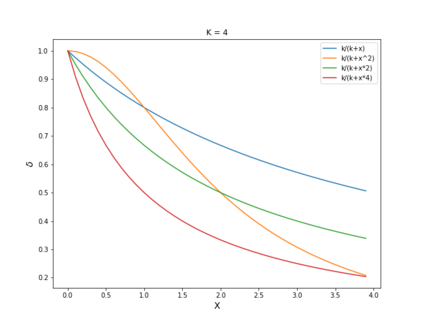
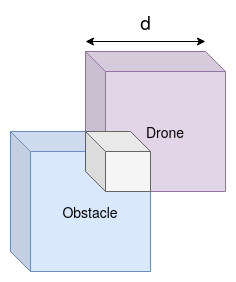
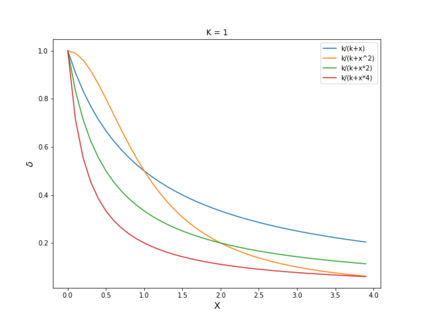
Autonomous drone swarms are a burgeoning technology with significant applications in the field of mapping, inspection, transportation and monitoring. To complete a task, each drone has to accomplish a sub-goal within the context of the overall task at hand and navigate through the environment by avoiding collision with obstacles and with other agents in the environment. In this work, we choose the task of optimal coverage of an environment with drone swarms where the global knowledge of the goal states and its positions are known but not of the obstacles. The drones have to choose the Points of Interest (PoI) present in the environment to visit, along with the order to be visited to ensure fast coverage. We model this task in a simulation and use an agent-oriented approach to solve the problem. We evaluate different policy networks trained with reinforcement learning algorithms based on their effectiveness, i.e. time taken to map the area and efficiency, i.e. computational requirements. We couple the task assignment with path planning in an unique way for performing collision avoidance during navigation and compare a grid-based global planning algorithm, i.e. Wavefront and a gradient-based local planning algorithm, i.e. Potential Field. We also evaluate the Potential Field planning algorithm with different cost functions, propose a method to adaptively modify the velocity of the drone when using the Huber loss function to perform collision avoidance and observe its effect on the trajectory of the drones. We demonstrate our experiments in 2D and 3D simulations.
翻译:自动无人驾驶飞机群是一个新兴技术,在绘图、检查、运输和监测领域应用了大量技术。为了完成任务,每个无人驾驶飞机都必须通过避免与障碍和环境中的其他物剂相撞,在目前的总体任务范围内完成一个次级目标,避免与障碍和环境中的其他物剂相撞。在这项工作中,我们选择以无人驾驶飞机群为最佳覆盖环境,让全球了解目标国及其位置,而不是障碍。无人驾驶飞机必须选择环境中的利益点(POI)进行访问,同时进行访问,以确保快速覆盖。我们以模拟方式执行这项任务,并采用面向代理人的方法解决问题。我们根据不同政策网络的效能,即绘制区域和效率图的时间,即计算要求,对任务分配与路径规划相结合,在导航期间以独特的方式进行避免碰撞,并将基于网络的全球规划算法进行比较,以确保快速覆盖。我们用模拟和基于梯度的本地规划算法来模拟这一任务,并使用面向代理人的办法来解决问题。我们评估了不同的学习算法,即用不同的成本算法来改变飞行轨道,然后用不同的飞行算法来改变飞行轨道。