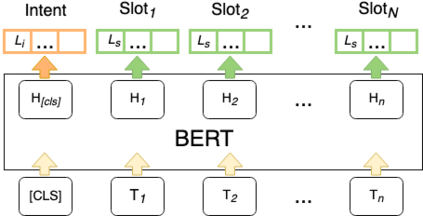
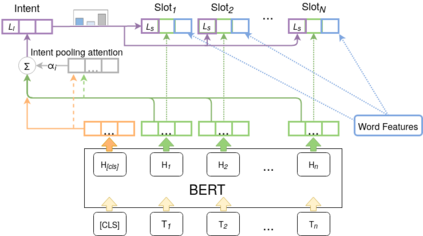
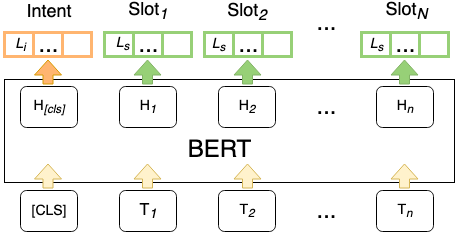
Detecting the user's intent and finding the corresponding slots among the utterance's words are important tasks in natural language understanding. Their interconnected nature makes their joint modeling a standard part of training such models. Moreover, data scarceness and specialized vocabularies pose additional challenges. Recently, the advances in pre-trained language models, namely contextualized models such as ELMo and BERT have revolutionized the field by tapping the potential of training very large models with just a few steps of fine-tuning on a task-specific dataset. Here, we leverage such models, namely BERT and RoBERTa, and we design a novel architecture on top of them. Moreover, we propose an intent pooling attention mechanism, and we reinforce the slot filling task by fusing intent distributions, word features, and token representations. The experimental results on standard datasets show that our model outperforms both the current non-BERT state of the art as well as some stronger BERT-based baselines.
翻译:在自然语言理解方面,发现用户的意图和查找发声词中相应的空档是重要的任务。它们的相互联系性质使得它们共同建模成为培训这类模型的标准部分。此外,数据稀缺和专门词汇构成更多的挑战。最近,预先培训的语言模型,即ELMO和BERT等背景化模型的进步,通过挖掘培训非常大型模型的潜力,对具体任务数据集只进行几步微调,使这个领域发生革命性的变化。在这里,我们利用这些模型,即BERT和ROBERTA, 并且我们设计了一个新的结构。此外,我们提出了一个意图集中关注机制,我们通过使用意向分布、字面特征和象征性表示来强化空档填充任务。标准数据集的实验结果表明,我们的模型超越了目前非ERT的科技状态以及基于BERT的更强大的基线。