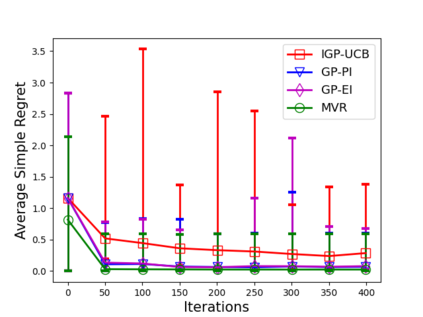
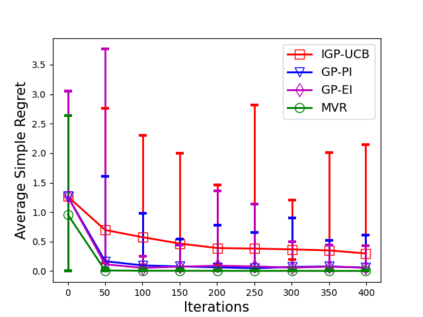
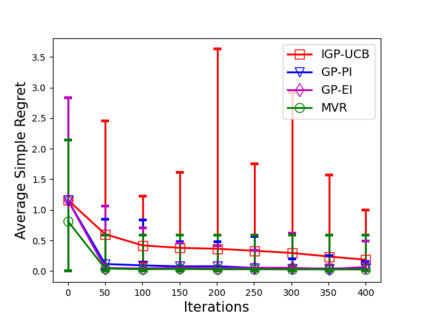
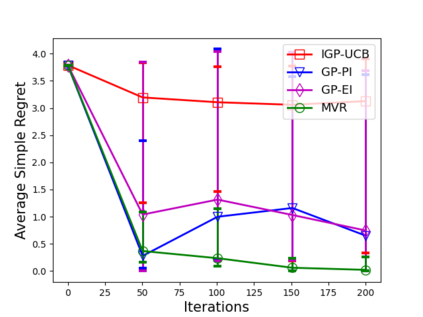
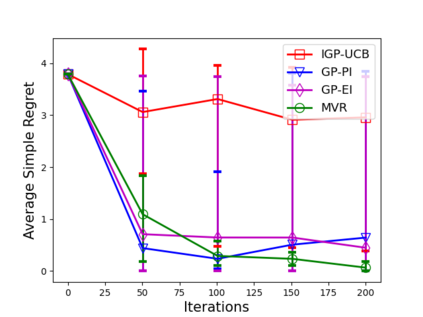
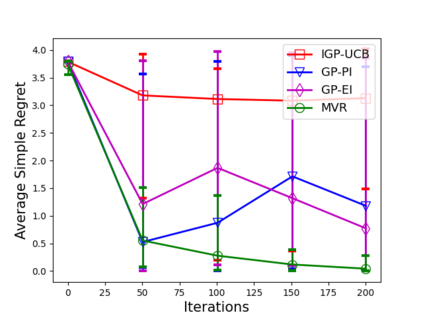
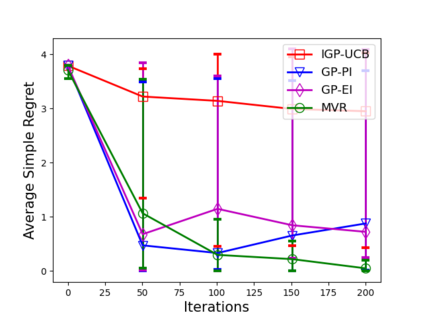
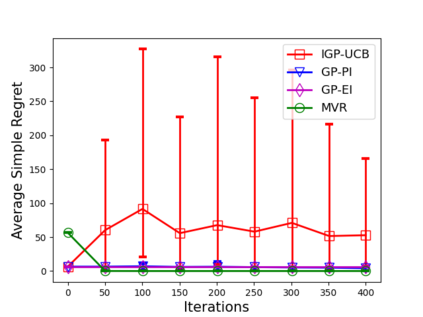
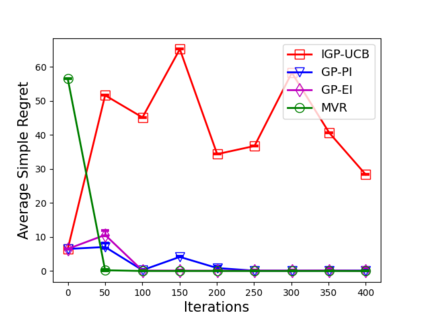
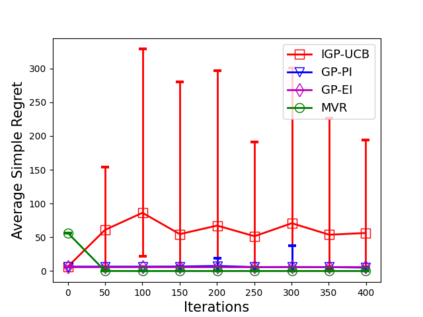
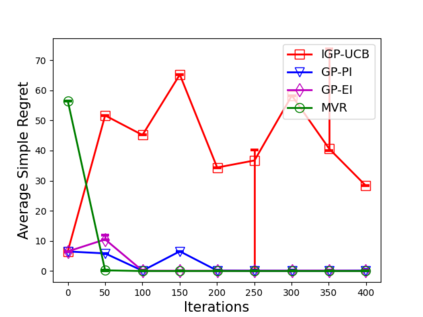
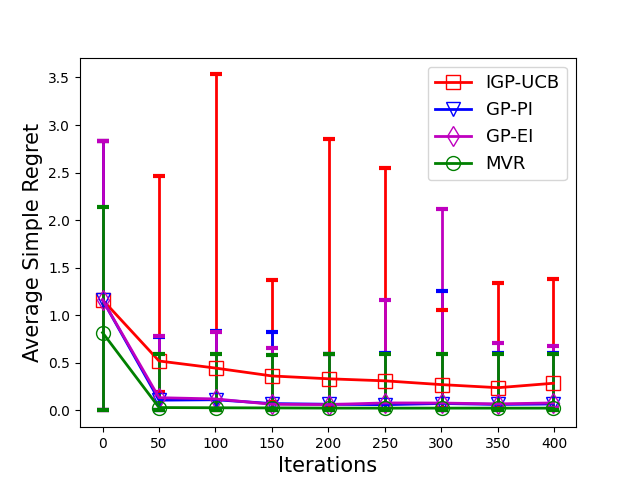
Consider the sequential optimization of a continuous, possibly non-convex, and expensive to evaluate objective function $f$. The problem can be cast as a Gaussian Process (GP) bandit where $f$ lives in a reproducing kernel Hilbert space (RKHS). The state of the art analysis of several learning algorithms shows a significant gap between the lower and upper bounds on the simple regret performance. When $N$ is the number of exploration trials and $\gamma_N$ is the maximal information gain, we prove an $\tilde{\mathcal{O}}(\sqrt{\gamma_N/N})$ bound on the simple regret performance of a pure exploration algorithm that is significantly tighter than the existing bounds. We show that this bound is order optimal up to logarithmic factors for the cases where a lower bound on regret is known. To establish these results, we prove novel and sharp confidence intervals for GP models applicable to RKHS elements which may be of broader interest.
翻译:考虑一个连续的, 可能是非convex, 并且用来评估客观功能的昂贵费用。 问题可以被描绘成一个高斯进程( GP) 土匪, $f 住在复制的Hilbert 空间( RKHS ) 。 一些学习算法的最新分析显示, 在简单的遗憾表现上, 下限和上限之间有很大差距。 当美元是勘探试验的数量, $\gamma_N$是最大的信息收益时, 我们证明, $\ tilde ~mathcal{ O{ (\\\\\\\ sqrt\ gamma_N/N} 绑在纯粹探索算法的简单遗憾表现上, 它比现有的界限要紧得多。 我们证明, 这个约束是最佳的逻辑因素, 对于已知的遗憾程度较低的案例来说, 。 为了确定这些结果, 我们证明适用于 RKHS 元素的G 模型有新颖和强烈的信任期。