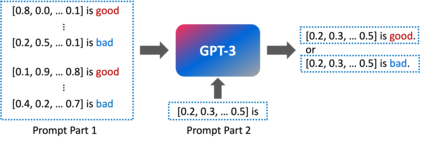
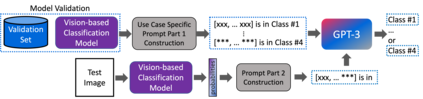
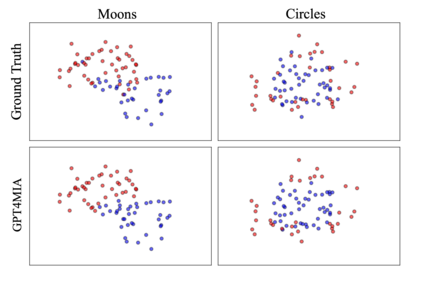
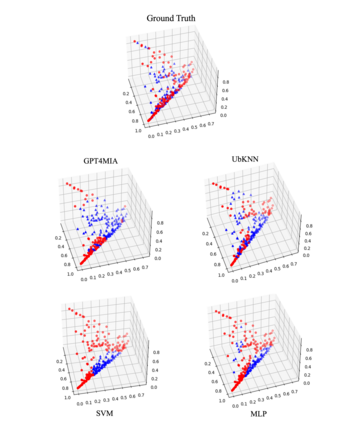
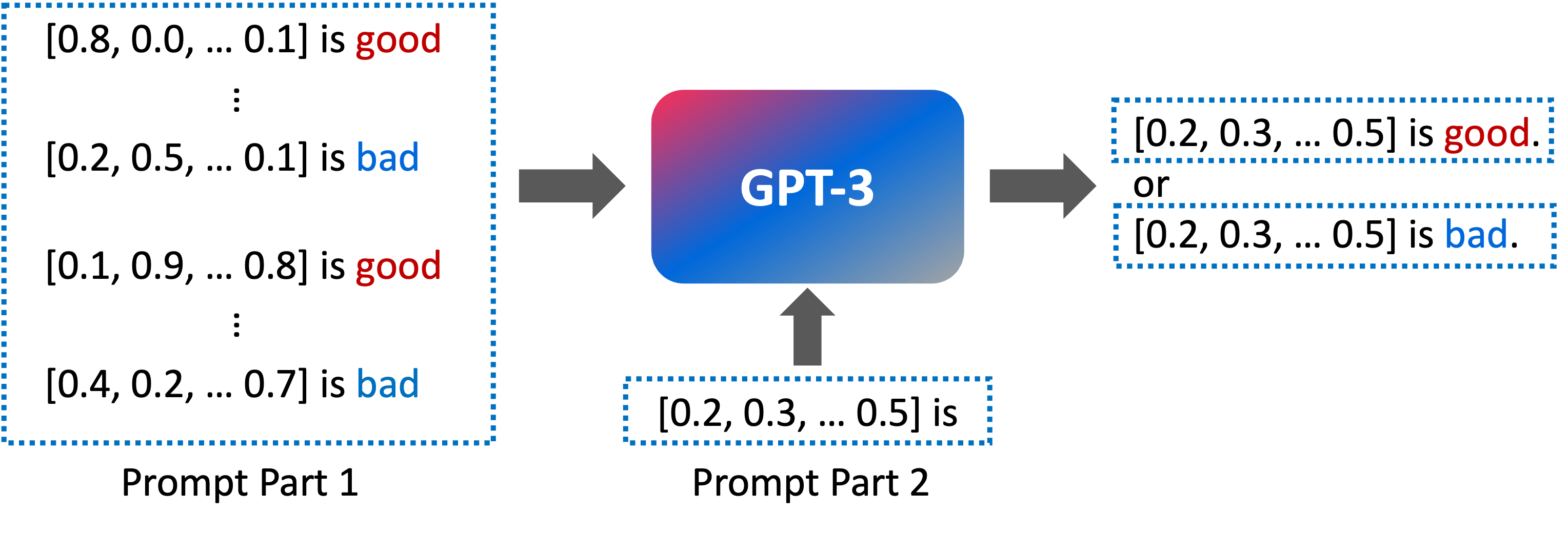
In this paper, we propose a novel approach (called GPT4MIA) that utilizes Generative Pre-trained Transformer (GPT) as a plug-and-play transductive inference tool for medical image analysis (MIA). We provide theoretical analysis on why a large pre-trained language model such as GPT-3 can be used as a plug-and-play transductive inference model for MIA. At the methodological level, we develop several technical treatments to improve the efficiency and effectiveness of GPT4MIA, including better prompt structure design, sample selection, and prompt ordering of representative samples/features. We present two concrete use cases (with workflow) of GPT4MIA: (1) detecting prediction errors and (2) improving prediction accuracy, working in conjecture with well-established vision-based models for image classification (e.g., ResNet). Experiments validate that our proposed method is effective for these two tasks. We further discuss the opportunities and challenges in utilizing Transformer-based large language models for broader MIA applications.
翻译:本文提出了一种新方法(称为GPT4MIA),利用生成式预训练转换器(GPT)作为医学图像分析(MIA)的即插即用传导推断工具。我们在理论分析层面上研究了一个如 GPT-3 这样的大型预训练语言模型为何可以用作 MIA 的即插即用传导推断模型。在方法论层面上,我们开发了几种技术处理方式,以提高 GPT4MIA 的效率和有效性,包括更好的提示结构设计、样本选择和代表性样本/特征的提示排序。我们呈现了 GPT4MIA 的两个具体用例(附有工作流):(1) 检测预测错误和 (2) 改善预测准确性,与基于视觉的成熟图像分类模型(如ResNet)相结合。实验验证了我们提出的方法对这两个任务的有效性。我们进一步探讨了利用基于转换器的大型语言模型进行更广泛 MIA 应用的机遇和挑战。