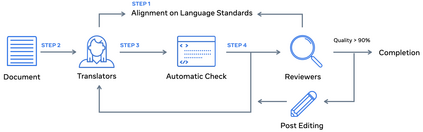
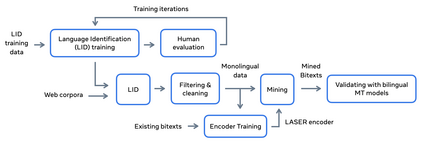
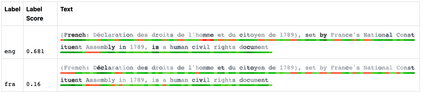
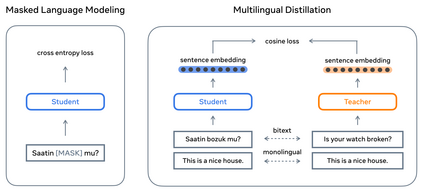
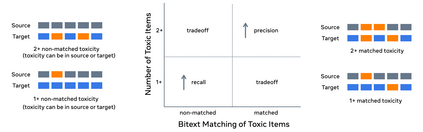
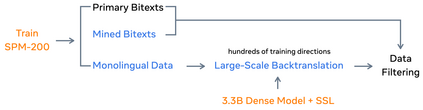
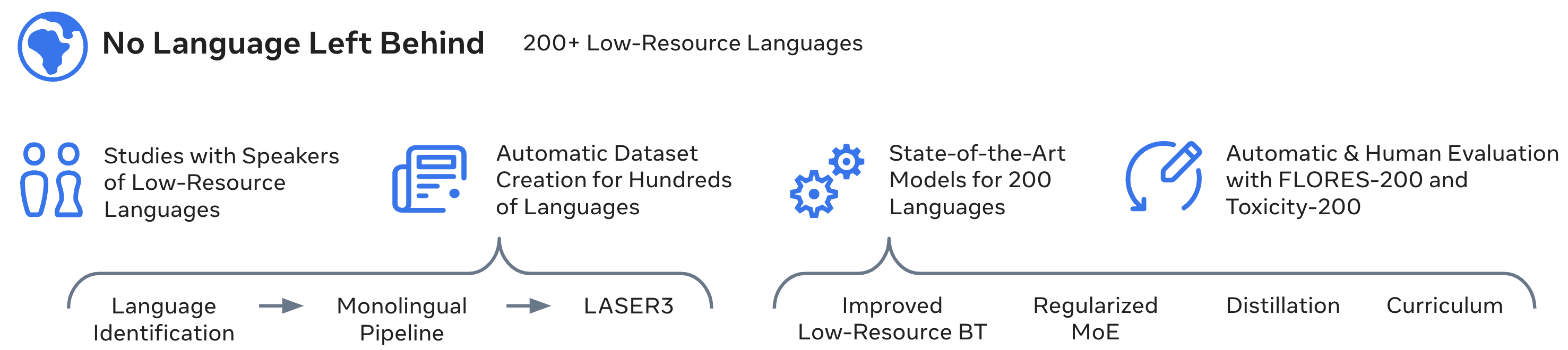
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
翻译:在全球范围消除语言障碍的目标推动下,机器翻译作为当今人工智能研究的关键焦点已经牢固地成为了人工智能研究的关键焦点。然而,这种努力已经围绕少数几组语言而凝聚起来,留下大部分资源较少的语言。打破200种语言障碍,同时确保安全、高质量的结果,同时牢记道德考量,这需要多少?在不留下任何语言的情况下,我们迎接这一挑战,首先通过与当地语言者进行探索性访谈,将低资源语言翻译支持的需求背景化。然后,我们创建了数据集和模型,旨在缩小低资源语言与高资源语言之间的性能差距。更具体地说,我们开发了一种有条件的折叠装模型,以简单化的专家混音模型为基础,该模型以新颖和有效的数据挖掘技术获得的数据,以低资源语言提供高质量的结果。我们提出了多项建筑和培训改进建议,以便在培训数千项任务的同时,用人文/翻译基准Flores-200将40 000多种不同翻译方向的绩效与新的毒性基准相结合。我们开发了一个有条件的模型,在Flores-200年/200年版本中将所有语言的毒性基准进行翻版翻译,最后将44年版的版本用于欧盟的重要版本。我们实现了基础的版本。