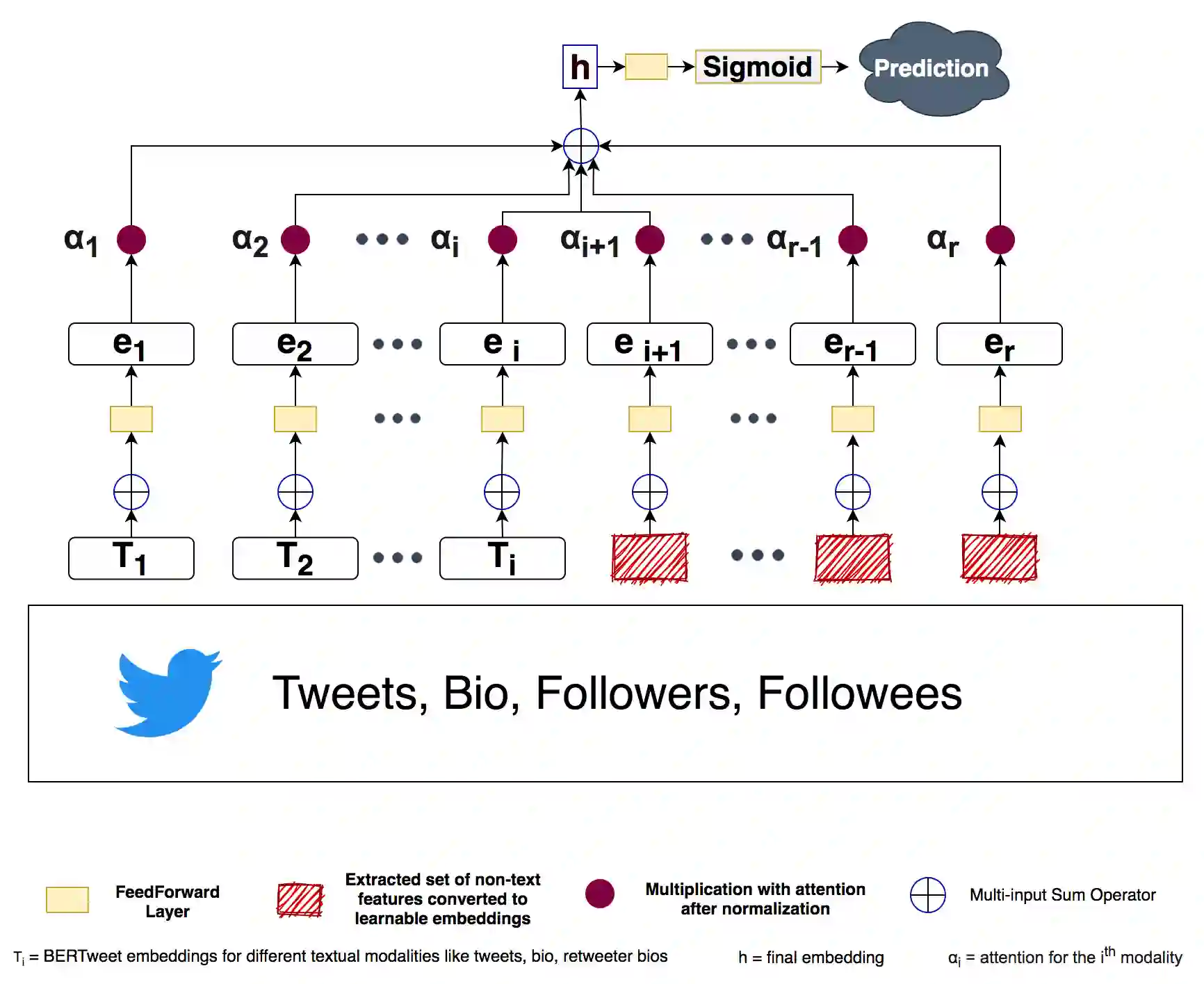
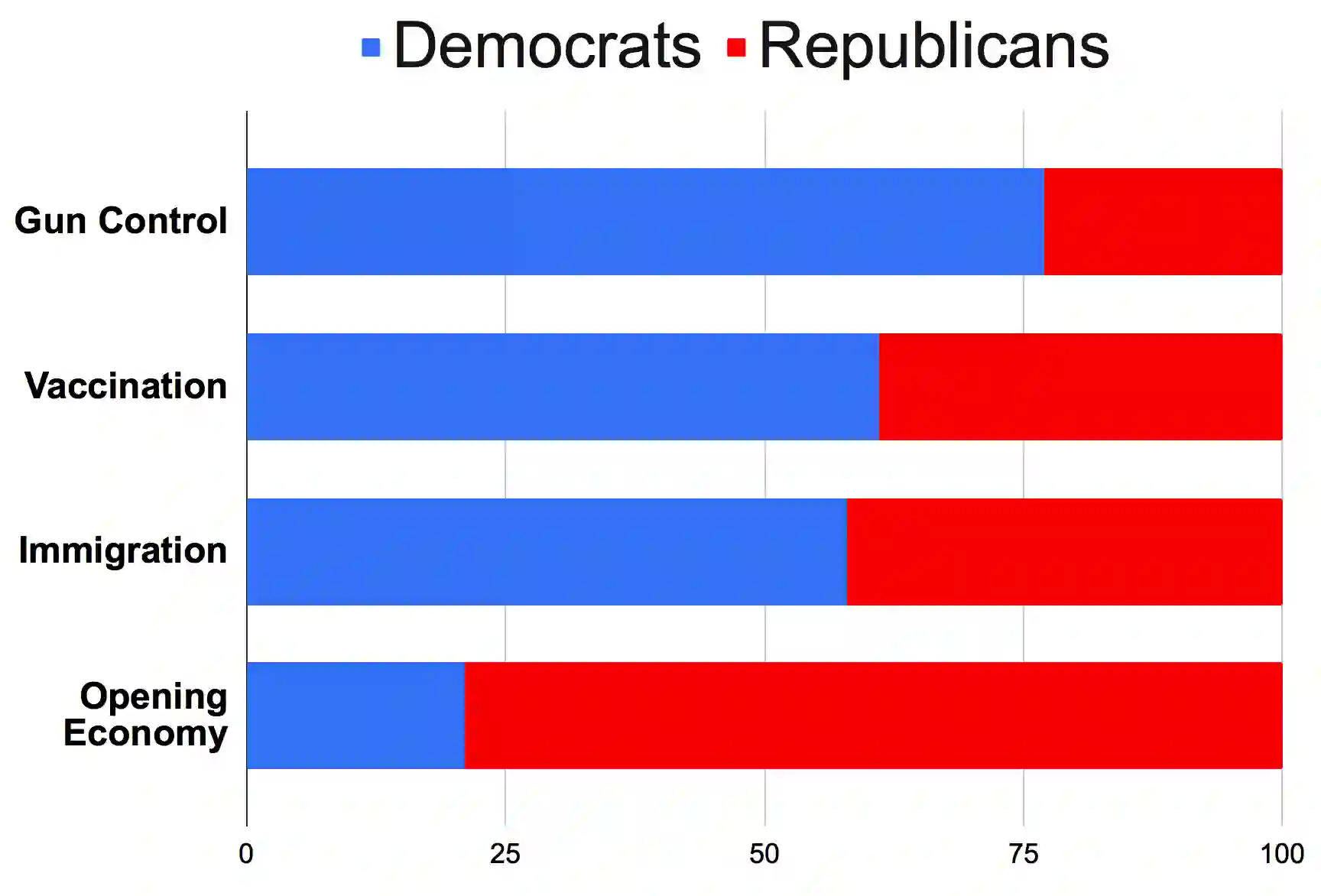
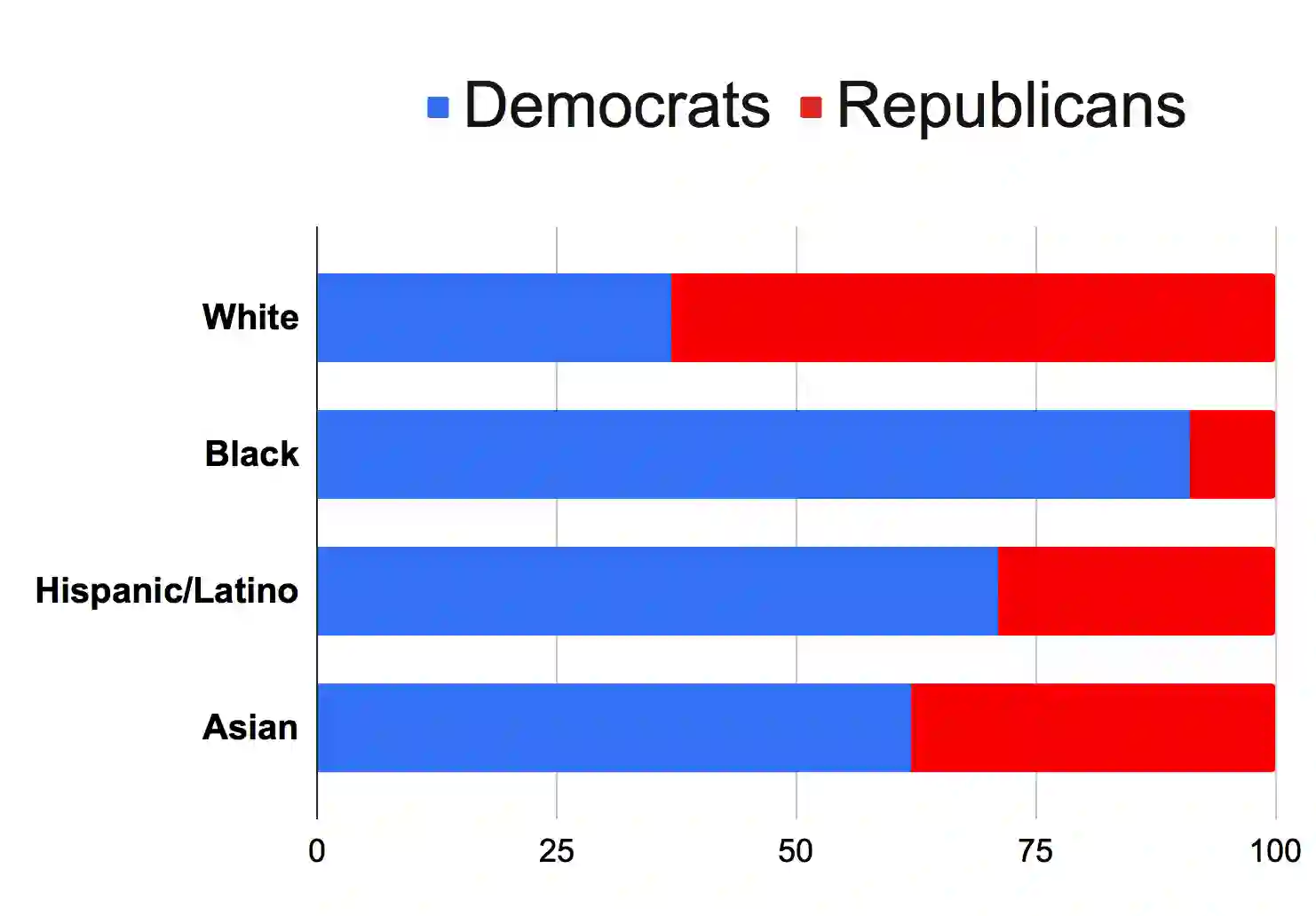
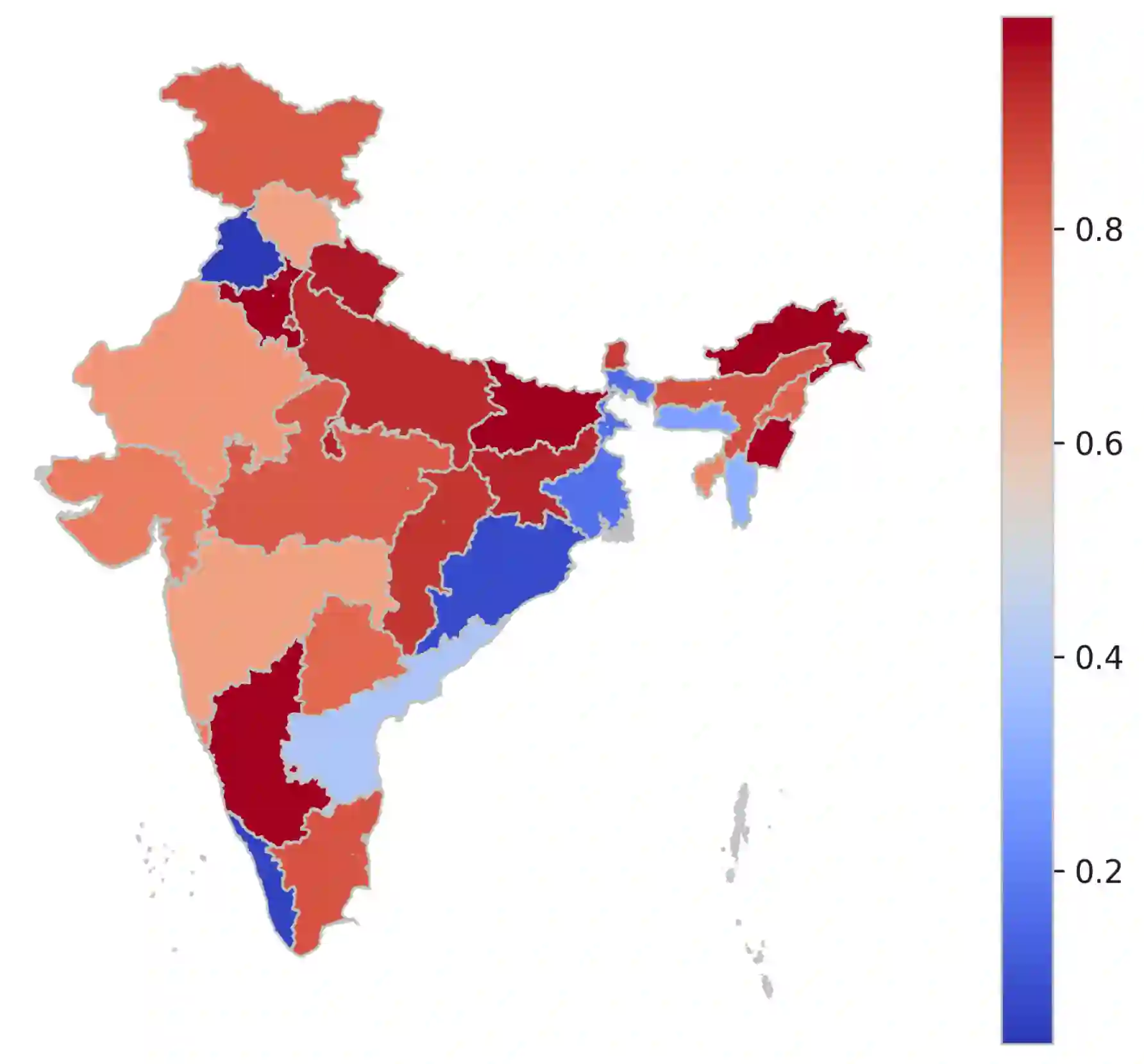
With the rising participation of the common mass in social media, it is increasingly common now for policymakers/journalists to create online polls on social media to understand the political leanings of people in specific locations. The caveat here is that only influential people can make such an online polling and reach out at a mass scale. Further, in such cases, the distribution of voters is not controllable and may be, in fact, biased. On the other hand,if we can interpret the publicly available data over social media to probe the political inclination of users, we will be able to have controllable insights about the survey population, keep the cost of survey low and also collect publicly available data without involving the concerned persons. Hence we introduce a self-attentive semi-supervised framework for political inclination detection to further that objective. The advantage of our model is that it neither needs huge training data nor does it need to store social network parameters. Nevertheless, it achieves an accuracy of 93.7\% with no annotated data; further, with only a few annotated examples per class it achieves competitive performance. We found that the model is highly efficient even in resource-constrained settings, and insights drawn from its predictions match the manual survey outcomes when applied to diverse real-life scenarios.
翻译:随着普通大众在社交媒体中的参与程度的提高,决策者/记者现在越来越普遍地在社交媒体上建立在线民意测验,以了解特定地点民众的政治倾向。这里的告诫是,只有有影响力的人才能进行这种在线民意测验和大规模接触。此外,在这种情况下,选民的分布是无法控制的,而且实际上可能存在偏差。另一方面,如果我们能够解释社交媒体上公开提供的数据,以探究用户的政治倾向,我们就能对调查人口有可控的洞察力,保持调查费用低廉,并在没有相关人员参与的情况下收集公开的数据。因此,我们引入了一个自我强化的半监督半监督框架,以探明政治倾向,从而推进这一目标。我们的模型的优点是,既不需要大量的培训数据,也不需要存储社交网络参数。然而,它实现了93.7 ⁇ 的准确度,没有附加说明的数据;此外,我们只能通过每个阶层的附加注释的例子来取得竞争性的业绩。我们发现,即使在资源紧张的环境下,模型也非常高效地应用到实际的手册和从预测中得到的洞察力。