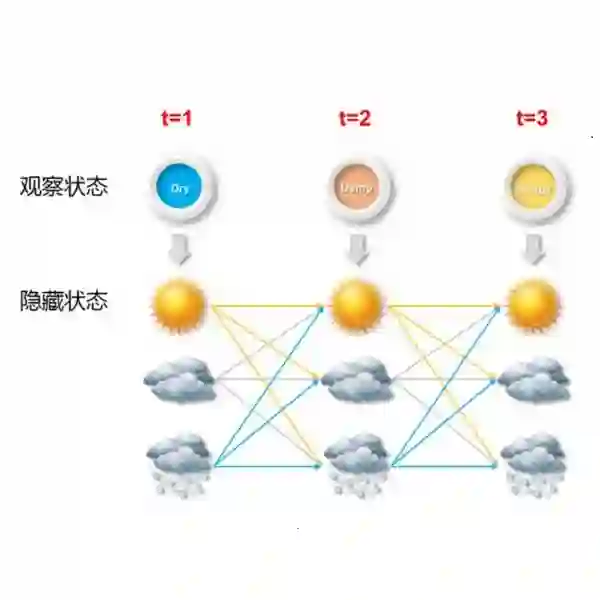
Markov chain Monte Carlo (MCMC) algorithms for hidden Markov models often rely on the forward-backward sampler. This makes them computationally slow as the length of the time series increases, motivating the recent development of sub-sampling-based approaches. These approximate the full posterior by using small random subsequences of the data at each MCMC iteration within stochastic gradient MCMC. In the presence of imbalanced data resulting from rare latent states, subsequences often exclude rare latent state data, leading to inaccurate inference and prediction/detection of rare events. We propose a targeted sub-sampling (TASS) approach that over-samples observations corresponding to rare latent states when calculating the stochastic gradient of parameters associated with them. TASS uses an initial clustering of the data to construct subsequence weights that reduce the variance in gradient estimation. This leads to improved sampling efficiency, in particular in settings where the rare latent states correspond to extreme observations. We demonstrate substantial gains in predictive and inferential accuracy on real and synthetic examples.
翻译:Markov链 Monte Carlo (MCMCC) 隐藏的Markov 模型的算法往往依赖于前向后向取样器。 这使得这些算法随着时间序列的长度的延长而计算缓慢,从而促使最近开发了次抽样方法。 这些算法通过在随机梯度 MCMC 中使用每个监测模型数据的小随机分序列来接近整个后部。 在存在由稀有潜伏状态产生的不平衡数据的情况下, 后继结果往往排除了稀有潜伏状态数据, 从而导致稀有事件的不准确推论和预测/ 探测。 我们提出了一个有针对性的次抽样(TASS) 方法, 在计算与之相关的参数的随机梯度时, 过度抽样观测与稀有潜在状态相对应。 TASS 使用数据的初步组合来构建后继加权, 从而降低梯度估计的差异。 这导致取样效率的提高, 特别是在稀有潜伏状态与极端观察相匹配的情况下。 我们表明, 在真实和合成实例的预测和推断准确性方面, 在预测和推断准确性方面有重大进展。