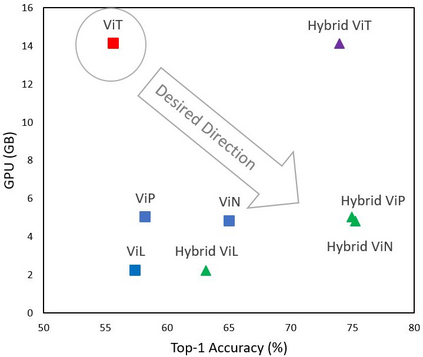
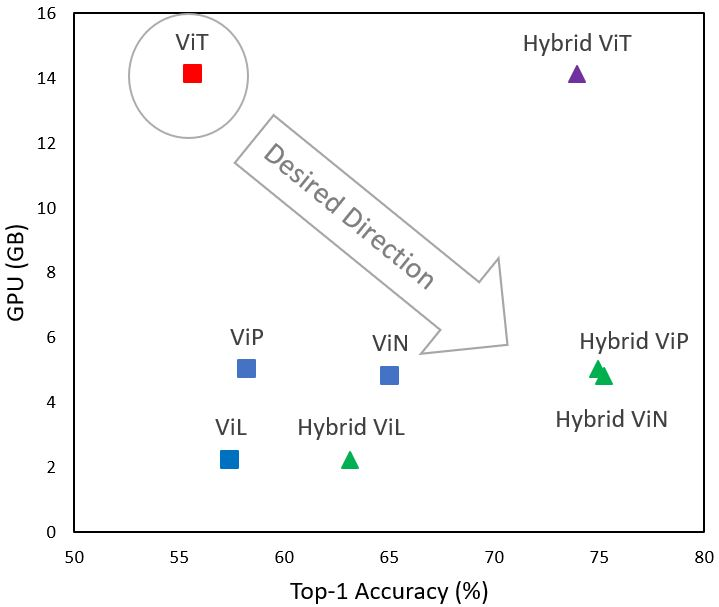
Although transformers have become the neural architectures of choice for natural language processing, they require orders of magnitude more training data, GPU memory, and computations in order to compete with convolutional neural networks for computer vision. The attention mechanism of transformers scales quadratically with the length of the input sequence, and unrolled images have long sequence lengths. Plus, transformers lack an inductive bias that is appropriate for images. We tested three modifications to vision transformer (ViT) architectures that address these shortcomings. Firstly, we alleviate the quadratic bottleneck by using linear attention mechanisms, called X-formers (such that, X in {Performer, Linformer, Nystr\"omformer}), thereby creating Vision X-formers (ViXs). This resulted in up to a seven times reduction in the GPU memory requirement. We also compared their performance with FNet and multi-layer perceptron mixers, which further reduced the GPU memory requirement. Secondly, we introduced an inductive bias for images by replacing the initial linear embedding layer by convolutional layers in ViX, which significantly increased classification accuracy without increasing the model size. Thirdly, we replaced the learnable 1D position embeddings in ViT with Rotary Position Embedding (RoPE), which increases the classification accuracy for the same model size. We believe that incorporating such changes can democratize transformers by making them accessible to those with limited data and computing resources.
翻译:虽然变压器已成为自然语言处理所选择的神经结构,但变压器已成为自然语言处理所选择的神经结构,它们需要数量级的更多培训数据、GPU内存和计算,以便与计算机视觉的进化神经网络竞争。变压器的注意机制随着输入序列长度的长度而以二次尺度衡量,而无滚动图像则有很长的序列长度。此外,变压器的性能缺乏适合图像的感应偏差。我们测试了用于解决这些缺陷的视觉变压器(ViT)结构的三项修改。首先,我们通过使用所谓的X-Ex(例如 {Perfrench, Linfer, Nystr\'omforth ) 的线性关注机制来减轻四进化瓶颈的瓶颈,从而与进动神经神经网络神经网络的X进行竞争。这导致对GPU的内存留要求减少七倍。我们还将其性与FNet和多层感应感应器混合器的性比较,从而进一步降低了GPU记忆要求。第二,我们引入了对图像的演化偏向偏向偏向性偏向性偏向,方法是用维X的线性嵌层层结构结构结构结构结构取代初始嵌入层,从而将ViX中的前层层层层结构层层层层层层结构,从而大大提升了这种变压变压式的变压式的变换取,这种变压式的定位。