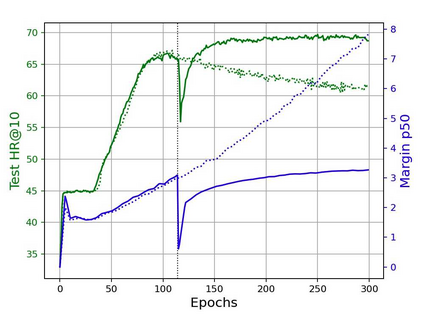
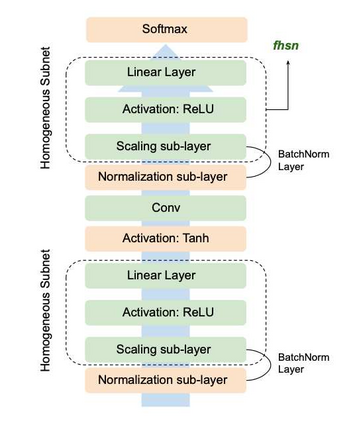
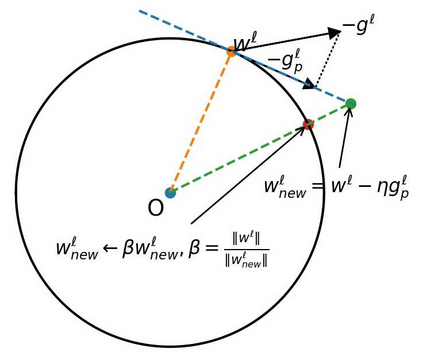
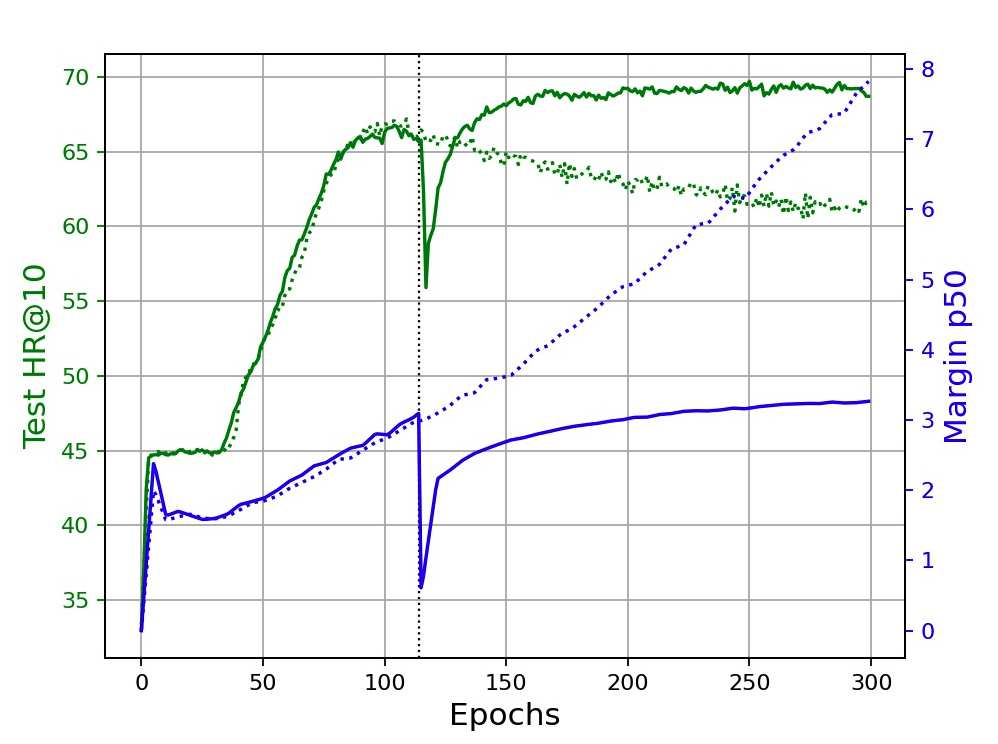
Over-parameterized deep networks trained using gradient-based optimizers are a popular choice for solving classification and ranking problems. Without appropriately tuned $\ell_2$ regularization or weight decay, such networks have the tendency to make output scores (logits) and network weights large, causing training loss to become too small and the network to lose its adaptivity (ability to move around) in the parameter space. Although regularization is typically understood from an overfitting perspective, we highlight its role in making the network more adaptive and enabling it to escape more easily from weights that generalize poorly. To provide such a capability, we propose a method called Logit Attenuating Weight Normalization (LAWN), that can be stacked onto any gradient-based optimizer. LAWN controls the logits by constraining the weight norms of layers in the final homogeneous sub-network. Empirically, we show that the resulting LAWN variant of the optimizer makes a deep network more adaptive to finding minimas with superior generalization performance on large-scale image classification and recommender systems. While LAWN is particularly impressive in improving Adam, it greatly improves all optimizers when used with large batch sizes
翻译:使用基于梯度的优化器所培训的超度深度网络是解决分类和排名问题的流行选择。不适当调整 $\ ell_ 2$ 正规化或重量衰减,这类网络倾向于使输出分数( logits) 和网络重量大得多,导致培训损失过小,网络在参数空间中失去适配性( 可移动性) 。虽然正规化通常从过分适当的角度理解,但我们强调其作用,使网络更适应性更强,使其更容易从普遍化不足的重量中逃脱。为了提供这种能力,我们建议了一种名为Logit Attatening Weight 正常化(LAWN) 的方法,这种方法可以堆积到任何基于梯度的优化器上。 法律网通过限制最终同质子网络各层的重量规范来控制对日志的对日志进行控制。 我们很生动地表明,由此形成的优化的LAPN变式使深网络更适应性,以找到在大型图像分类和建议系统中具有超超常化性性功能的微型。在改进亚当方面特别令人印象深刻。当改进亚当时,它能大大改进了所有与大批量使用时,它大大改进了所有优化。