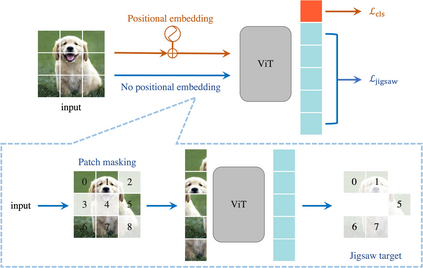
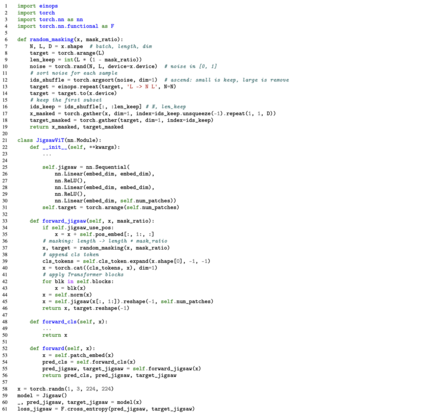
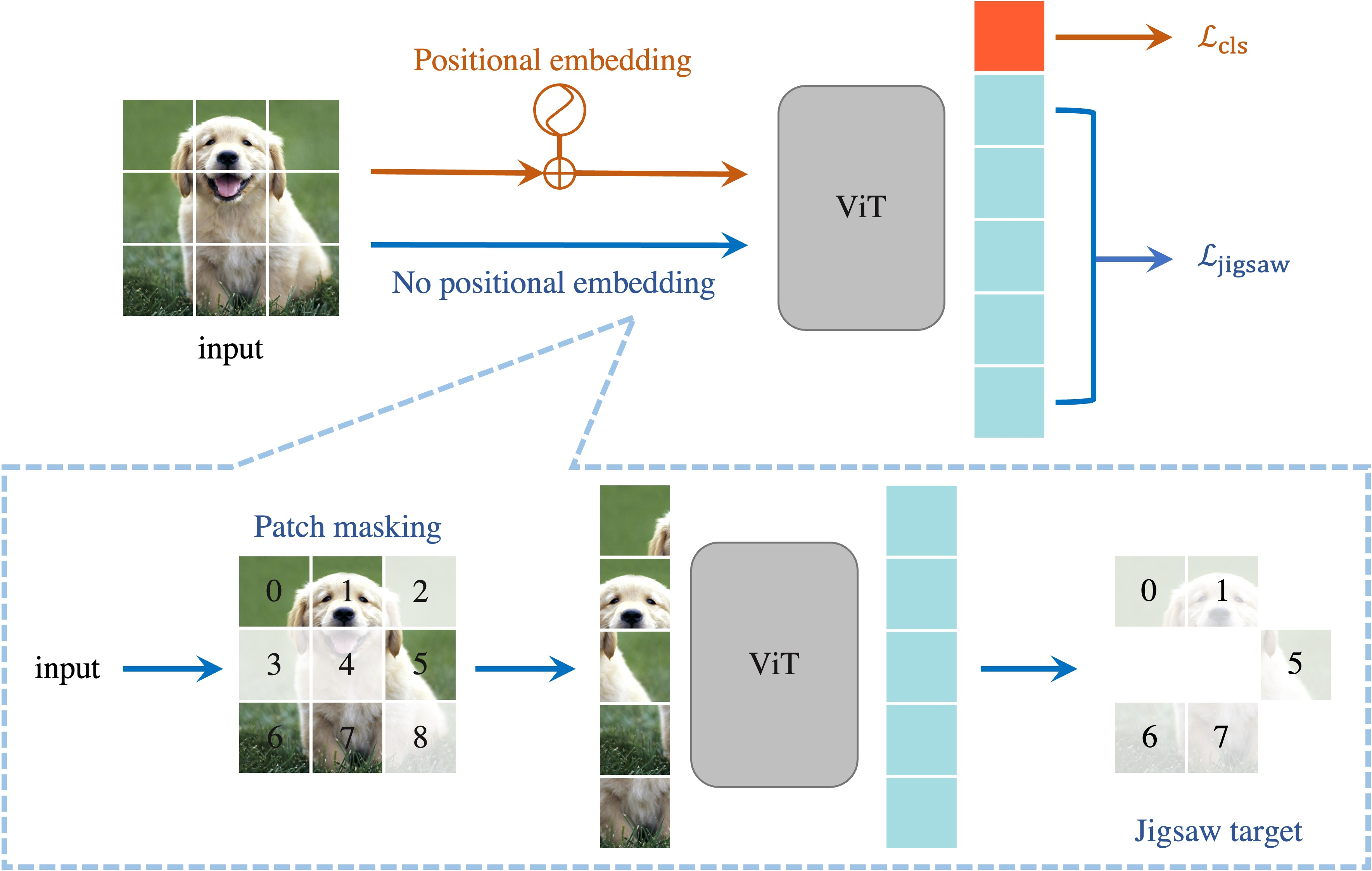
The success of Vision Transformer (ViT) in various computer vision tasks has promoted the ever-increasing prevalence of this convolution-free network. The fact that ViT works on image patches makes it potentially relevant to the problem of jigsaw puzzle solving, which is a classical self-supervised task aiming at reordering shuffled sequential image patches back to their natural form. Despite its simplicity, solving jigsaw puzzle has been demonstrated to be helpful for diverse tasks using Convolutional Neural Networks (CNNs), such as self-supervised feature representation learning, domain generalization, and fine-grained classification. In this paper, we explore solving jigsaw puzzle as a self-supervised auxiliary loss in ViT for image classification, named Jigsaw-ViT. We show two modifications that can make Jigsaw-ViT superior to standard ViT: discarding positional embeddings and masking patches randomly. Yet simple, we find that Jigsaw-ViT is able to improve both in generalization and robustness over the standard ViT, which is usually rather a trade-off. Experimentally, we show that adding the jigsaw puzzle branch provides better generalization than ViT on large-scale image classification on ImageNet. Moreover, the auxiliary task also improves robustness to noisy labels on Animal-10N, Food-101N, and Clothing1M as well as adversarial examples. Our implementation is available at https://yingyichen-cyy.github.io/Jigsaw-ViT/.
翻译:视觉变异器(Vigs Greanger)在各种计算机视觉任务中的成功促进了这种无革命性网络的日益普及。 ViT在图像补丁上工作,使得它有可能与拼图解谜题问题相关,而拼图解谜题是一个典型的自我监督任务,目的是重新排序被打乱的连续图像补丁,使其恢复到自然形式。尽管它简单,但解决拼图拼图难题已证明有助于使用 Convolual Neal网络(CNNs)来完成各种任务,例如自我监督的特征演示学习、域域域化和精细的分类。在本文中,我们探讨将拼图拼图拼图拼图作为维格解解解谜的一个自监督的辅助损失来解决。 我们展示了两个修改,使 Jigsaw-ViT 高于标准格式: 丢弃定位嵌嵌入和随机掩蔽 。 然而, Jigsaw- Vialyalaling- Vialoff 能够改进标准ViT的通用和坚固度, 通常比交易/Sildal-LIal-Ial-Ialations 提供了一个更大规模的分类。