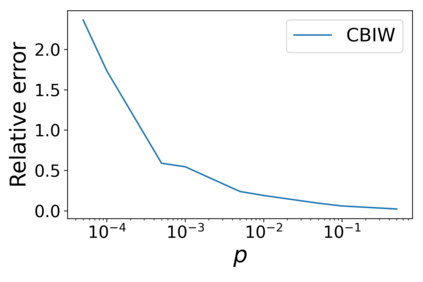
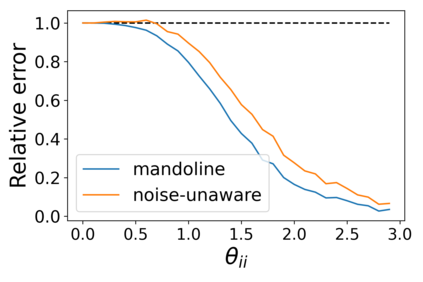
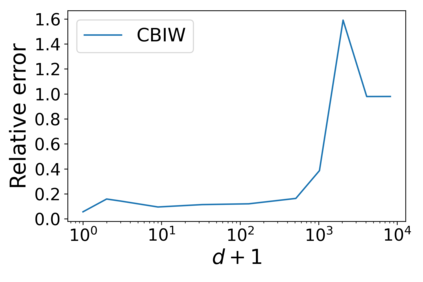
Machine learning models are often deployed in different settings than they were trained and validated on, posing a challenge to practitioners who wish to predict how well the deployed model will perform on a target distribution. If an unlabeled sample from the target distribution is available, along with a labeled sample from a possibly different source distribution, standard approaches such as importance weighting can be applied to estimate performance on the target. However, importance weighting struggles when the source and target distributions have non-overlapping support or are high-dimensional. Taking inspiration from fields such as epidemiology and polling, we develop Mandoline, a new evaluation framework that mitigates these issues. Our key insight is that practitioners may have prior knowledge about the ways in which the distribution shifts, which we can use to better guide the importance weighting procedure. Specifically, users write simple "slicing functions" - noisy, potentially correlated binary functions intended to capture possible axes of distribution shift - to compute reweighted performance estimates. We further describe a density ratio estimation framework for the slices and show how its estimation error scales with slice quality and dataset size. Empirical validation on NLP and vision tasks shows that \name can estimate performance on the target distribution up to $3\times$ more accurately compared to standard baselines.
翻译:机器学习模型往往在不同的环境下部署,而不是经过培训和验证,对希望预测所部署模型在目标分布上将取得多大成绩的从业人员提出了挑战。如果有目标分布的未贴标签样本,以及可能不同来源分布的标签样本,那么可以采用诸如重要性加权等标准方法来估计目标的绩效。然而,当源和目标分布得到不重叠的支持或具有高维度时,重要性加权的挣扎,我们从流行病学和民意测验等领域获得灵感,我们开发了曼度线,这是一个减轻这些问题的新评价框架。我们的主要见解是,从业人员可能事先知道分配变化的方式,我们可以使用这些方法来更好地指导重要性加权程序。具体地说,用户写简单的“授权功能”――噪音,可能相关的二元功能,目的是捕捉分布变化的可能轴心——计算再加权性估计。我们进一步描述切片的密度比率估计框架,并展示其估计误差的尺度如何用切质量和数据设置大小。NLP+愿景任务,在目标分布上比3的基线显示业绩估计数。