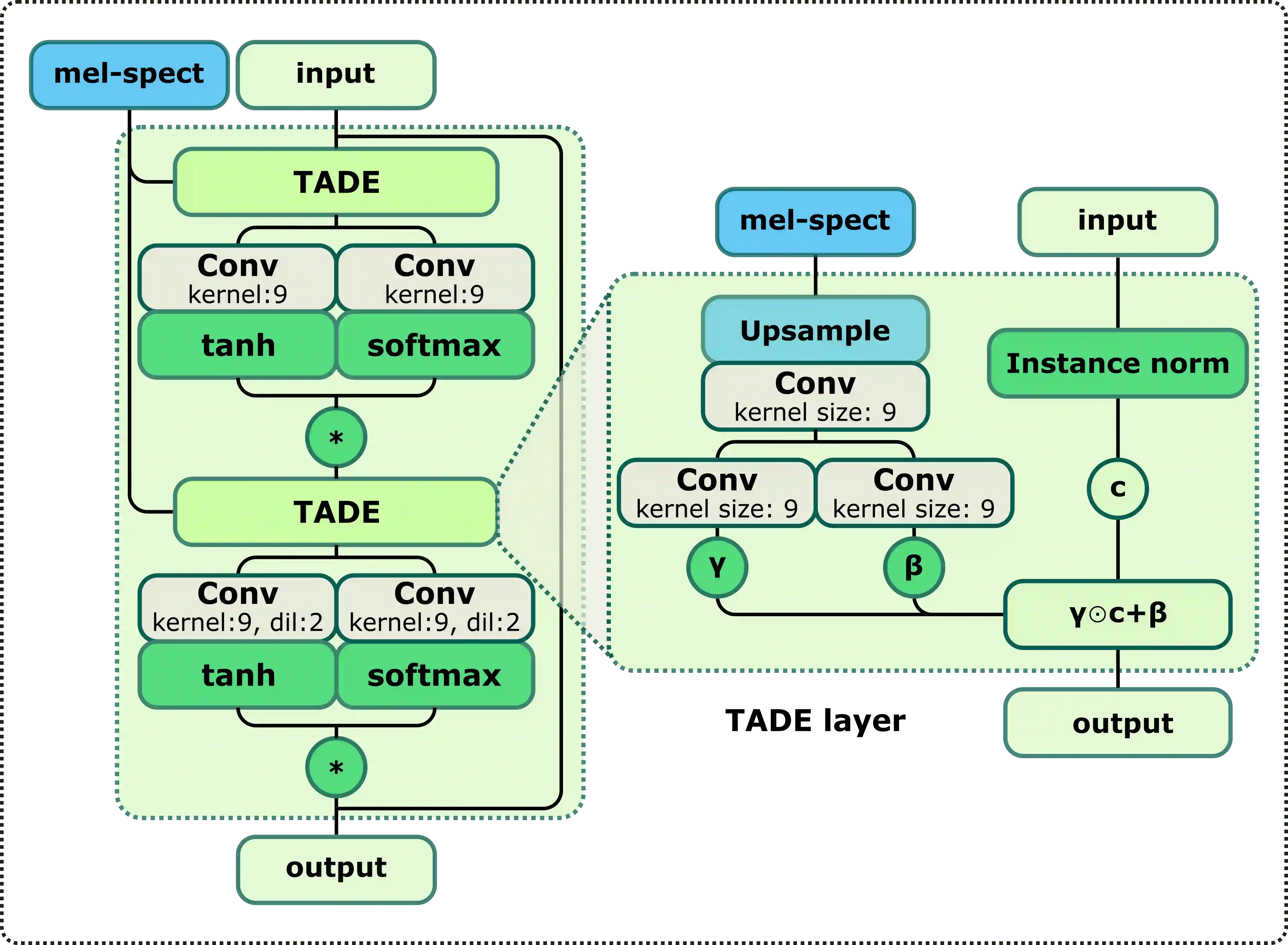
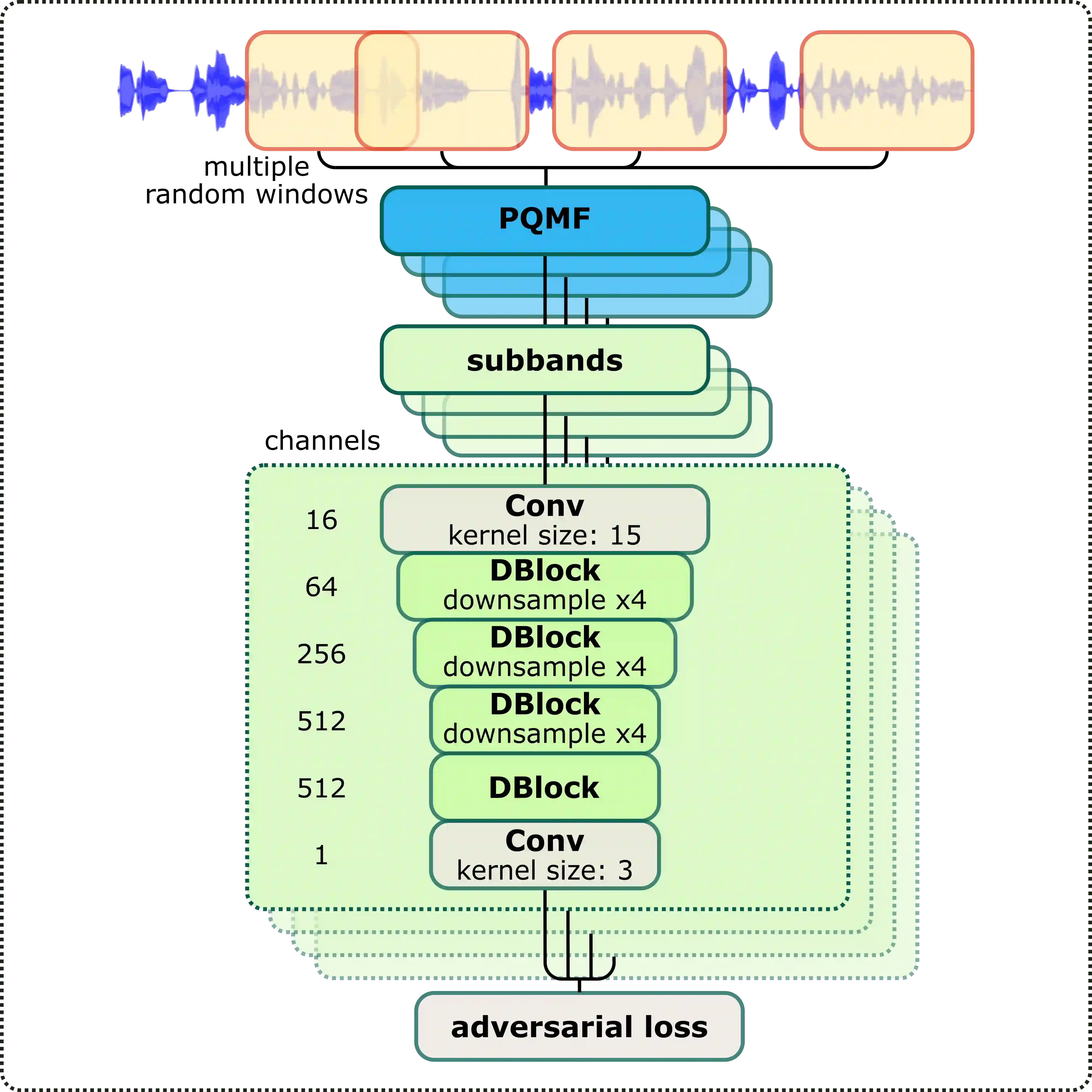
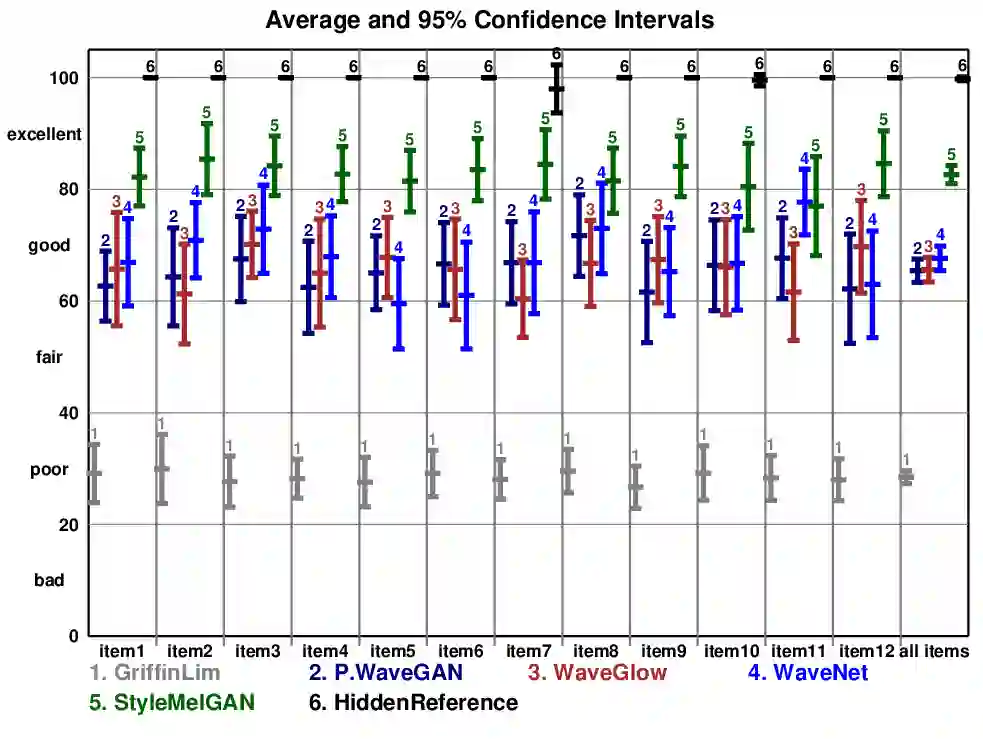
In recent years, neural vocoders have surpassed classical speech generation approaches in naturalness and perceptual quality of the synthesized speech. Computationally heavy models like WaveNet and WaveGlow achieve best results, while lightweight GAN models, e.g. MelGAN and Parallel WaveGAN, remain inferior in terms of perceptual quality. We therefore propose StyleMelGAN, a lightweight neural vocoder allowing synthesis of high-fidelity speech with low computational complexity. StyleMelGAN employs temporal adaptive normalization to style a low-dimensional noise vector with the acoustic features of the target speech. For efficient training, multiple random-window discriminators adversarially evaluate the speech signal analyzed by a filter bank, with regularization provided by a multi-scale spectral reconstruction loss. The highly parallelizable speech generation is several times faster than real-time on CPUs and GPUs. MUSHRA and P.800 listening tests show that StyleMelGAN outperforms prior neural vocoders in copy-synthesis and Text-to-Speech scenarios.
翻译:近些年来,神经电动器在合成语音的自然性和感知质量方面超过了典型的语音生成方法。WaveNet和WaveGlow等重度模型取得了最佳效果,而轻量级GAN模型,如MelGAN和平行WaveGAN等,在感知质量方面仍然低劣。因此,我们提议StyleMelGAN,一个轻量级神经电动器,可以将高纤维语言与低计算复杂度合成。StyleMelGAN采用时间适应性正常化,对带有目标演讲声学特征的低维度噪音矢量进行风格化。为了高效培训,多个随机窗口歧视者对由过滤库分析的语音信号进行对抗性评价,由多尺度光谱重建损失提供正规化。在CPUs和GPUPS上,高度平行的语音生成数倍于实时时间。MUSHRA和P.800听力测试显示SylMelGAN在复制和文本到Speet-Speech情景中超越了前神经变形。