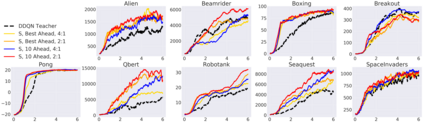
Learning from demonstrations is a popular tool for accelerating and reducing the exploration requirements of reinforcement learning. When providing expert demonstrations to human students, we know that the demonstrations must fall within a particular range of difficulties called the "Zone of Proximal Development (ZPD)". If they are too easy the student learns nothing, but if they are too difficult the student is unable to follow along. This raises the question: Given a set of potential demonstrators, which among them is best suited for teaching any particular learner? Prior work, such as the popular Deep Q-learning from Demonstrations (DQfD) algorithm has generally focused on single demonstrators. In this work we consider the problem of choosing among multiple demonstrators of varying skill levels. Our results align with intuition from human learners: it is not always the best policy to draw demonstrations from the best performing demonstrator (in terms of reward). We show that careful selection of teaching strategies can result in sample efficiency gains in the learner's environment across nine Atari games
翻译:从示威中学习是加速和减少强化学习的探索要求的流行工具。 当向人类学生提供专家演示时,我们知道示威必须属于所谓的“预产期发展区 ” ( ZPD) 的特殊困难范围。 如果示威过于容易,学生就什么也学不到,但是如果他们学习太困难,学生无法跟上来。 这就提出了一个问题 : 鉴于一组潜在的示威者,他们中最适合教授任何特定的学习者; 先前的工作, 如从演示中广受欢迎的深Q学习算法(DQfD), 通常侧重于单一的示威者。 在这项工作中,我们考虑在多种技能水平不同的示威者中选择问题。 我们的结果与人类学习者的直觉一致:从最优秀的表演者那里吸引示范并不是最好的政策(在奖励方面 ) 。 我们显示,仔细选择教学策略可以导致在9场阿塔里游戏中学习者环境中的抽样效率收益。