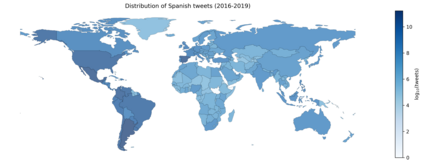
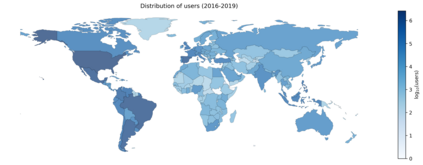
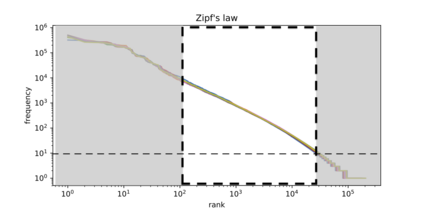
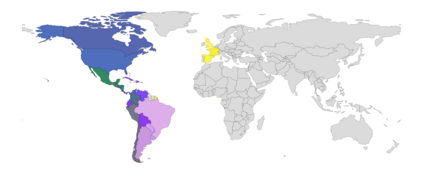
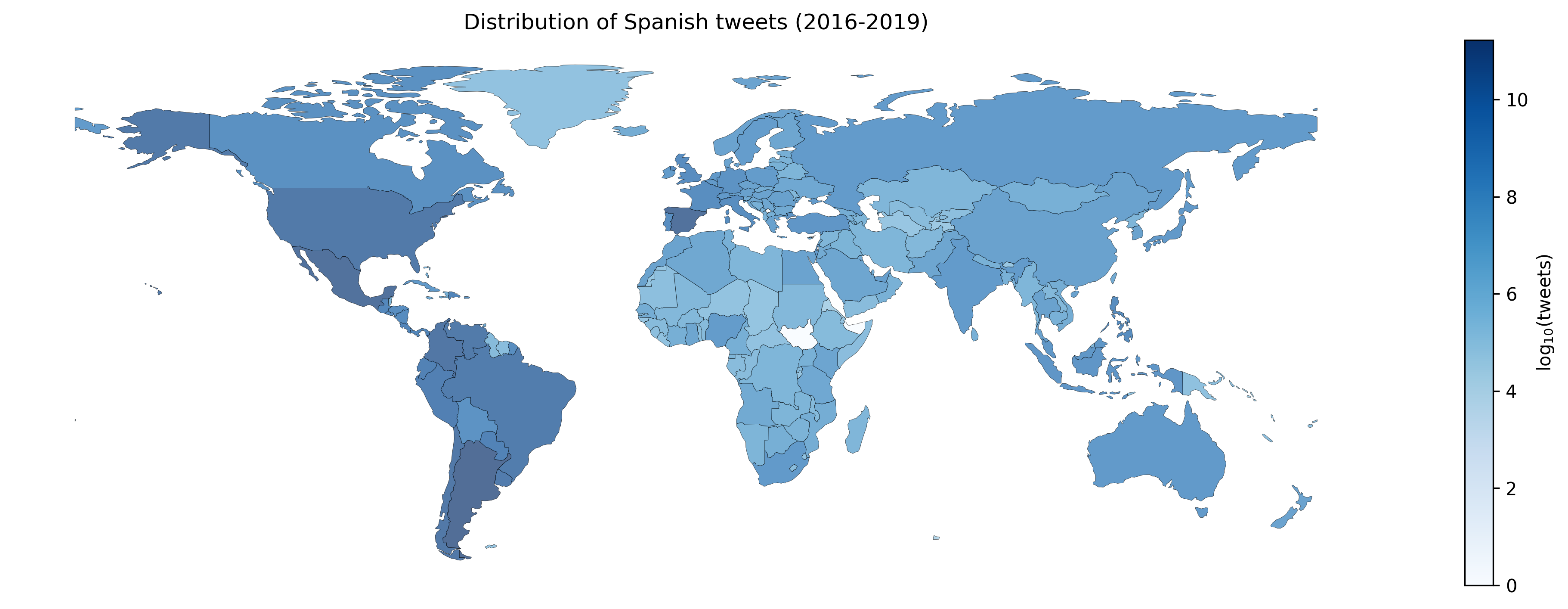
Spanish is one of the most spoken languages in the globe, but not necessarily Spanish is written and spoken in the same way in different countries. Understanding local language variations can help to improve model performances on regional tasks, both understanding local structures and also improving the message's content. For instance, think about a machine learning engineer who automatizes some language classification task on a particular region or a social scientist trying to understand a regional event with echoes on social media; both can take advantage of dialect-based language models to understand what is happening with more contextual information hence more precision. This manuscript presents and describes a set of regionalized resources for the Spanish language built on four-year Twitter public messages geotagged in 26 Spanish-speaking countries. We introduce word embeddings based on FastText, language models based on BERT, and per-region sample corpora. We also provide a broad comparison among regions covering lexical and semantical similarities; as well as examples of using regional resources on message classification tasks.
翻译:理解当地语言差异有助于改善区域任务模式的绩效,既了解当地结构,也改进信息内容。例如,考虑一个机器学习工程师,在特定区域将一些语言分类任务自动化,或考虑一个社会科学家,试图理解某个区域活动,在社交媒体上进行回声;两者都可以利用基于方言的语言模型,了解背景信息越多,情况就越精确。本手稿展示并描述一套西班牙语区域化资源,这些资源建在26个西班牙语国家的四年的推特公共信息上。我们引入基于快通、基于BERT的语言模型和每个区域样本的组合的词嵌入模式。我们还提供不同区域的广泛比较,涵盖词汇和语义上的相似之处;以及使用区域资源进行信息分类任务的实例。