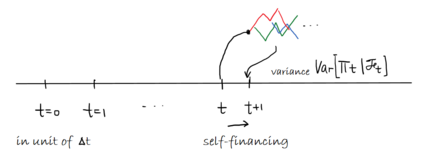
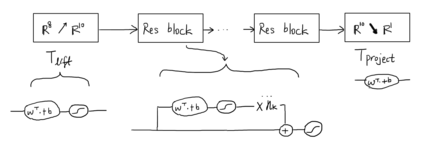
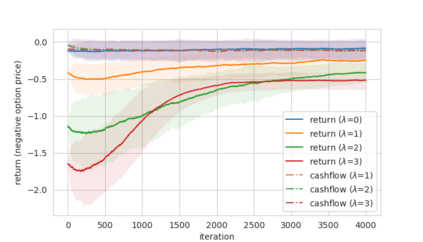
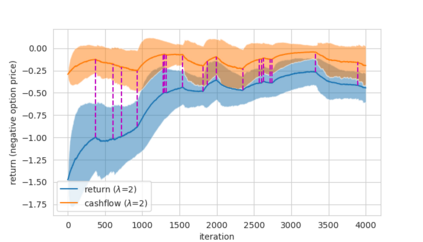
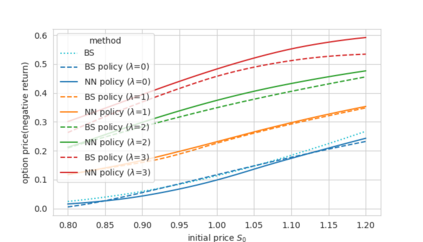
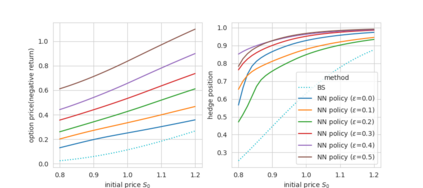
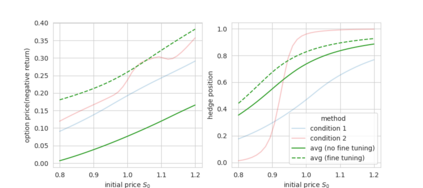
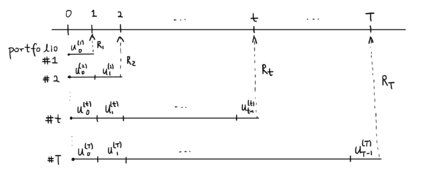
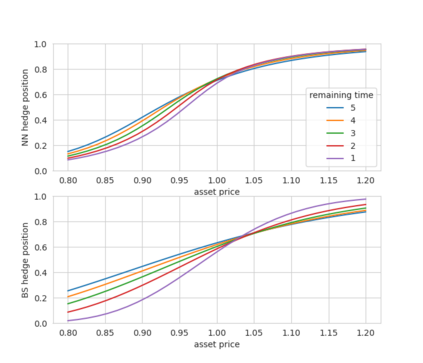
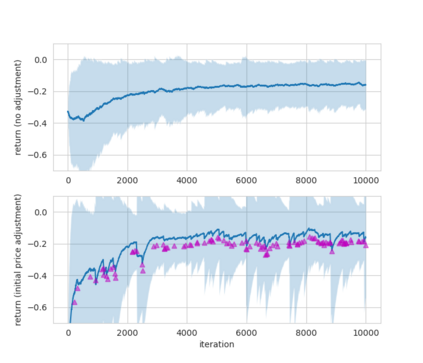
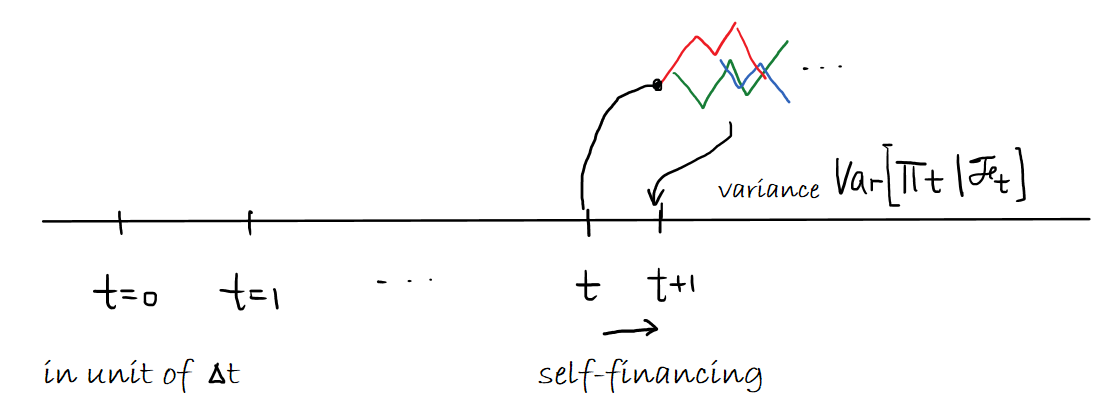
Abstract In this work, we build two environments, namely the modified QLBS and RLOP models, from a mathematics perspective which enables RL methods in option pricing through replicating by portfolio. We implement the environment specifications (the source code can be found at https://github.com/owen8877/RLOP), the learning algorithm, and agent parametrization by a neural network. The learned optimal hedging strategy is compared against the BS prediction. The effect of various factors is considered and studied based on how they affect the optimal price and position.
翻译:在这项工作中,我们从数学角度构建了两种环境,即经过修改的QLBS和RLOP模式,通过组合复制,使RL能够采用选择定价方法;我们实施环境规格(源代码见https://github.com/owen8877/RLOP),学习算法,以及神经网络的代理对称化;将学到的最佳对冲战略与BS预测进行比较;根据各种因素对最佳价格和位置的影响来考虑和研究各种因素的影响。