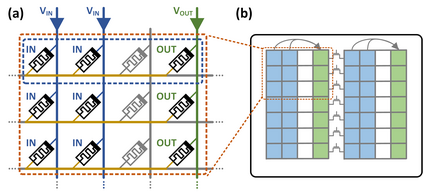
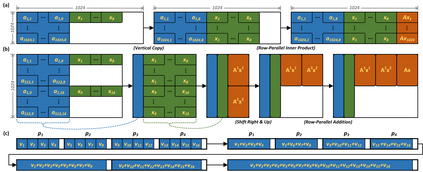
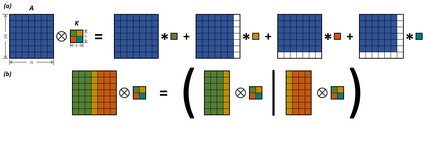
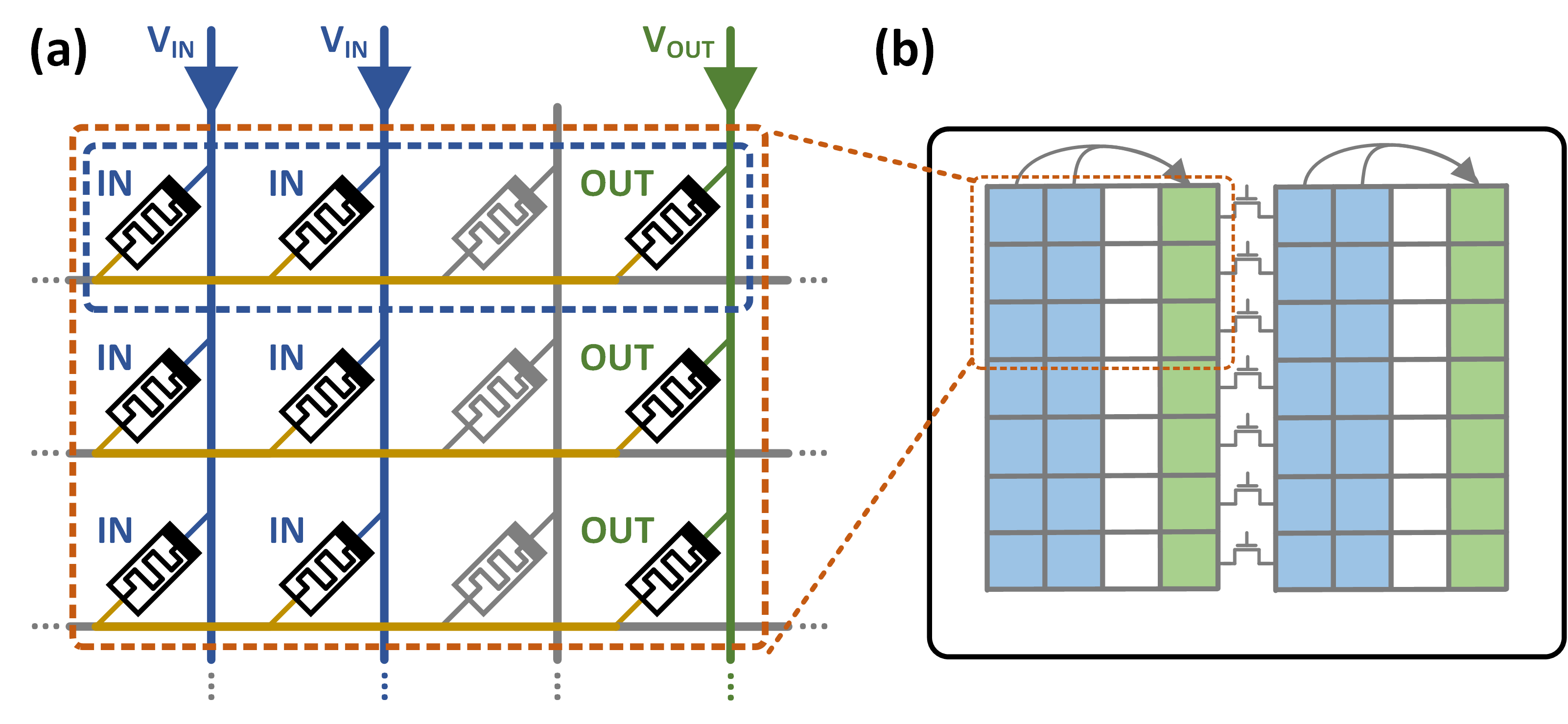
The emerging memristive Memory Processing Unit (mMPU) overcomes the memory wall through memristive devices that unite storage and logic for real processing-in-memory (PIM) systems. At the core of the mMPU is stateful logic, which is accelerated with memristive partitions to enable logic with massive inherent parallelism within crossbar arrays. This paper vastly accelerates the fundamental operations of matrix-vector multiplication and convolution in the mMPU, with either full-precision or binary elements. These proposed algorithms establish an efficient foundation for large-scale mMPU applications such as neural-networks, image processing, and numerical methods. We overcome the inherent asymmetry limitation in the previous in-memory full-precision matrix-vector multiplication solutions by utilizing techniques from block matrix multiplication and reduction. We present the first fast in-memory binary matrix-vector multiplication algorithm by utilizing memristive partitions with a tree-based popcount reduction (39x faster than previous work). For convolution, we present a novel in-memory input-parallel concept which we utilize for a full-precision algorithm that overcomes the asymmetry limitation in convolution, while also improving latency (2x faster than previous work), and the first fast binary algorithm (12x faster than previous work).
翻译:正在兴起的记忆存储处理器( MMPU) 克服了记忆墙。 正在形成的记忆处理器( MMPU), 通过将真实处理的系统存储和逻辑( PIM) 的存储和逻辑统一起来的记忆墙。 MMPU 的核心是清晰的逻辑, 其核心是隐含的分割加速, 使跨条阵列内大量固有平行的逻辑得以实现。 本文极大地加快了 mMPU 中矩阵- 矢量倍增和递增的基本操作, 包括完整精度或二进制元素。 这些拟议的算法为大型 mMPU 应用程序( 如神经网络、 图像处理和数字方法) 奠定了高效的基础。 我们克服了先前的模拟全精度全度矩阵矩阵增量解决方案中固有的不对称性限制。 我们通过使用基于树基快速的分解分解和速计数减少( 39x 速度快于先前的工作), 我们展示了在前一模范进程中进行新进化的进化进化算法( 2) 快速进化算法概念, 也利用了以前的进化进化进化进化进化进化进化进化进化分析器( 2) 的进化进化后, 进化的进化算法也使用了前的进化进化进化进化进化的进化的进化过程的进化过程的进化过程的进化过程的进化过程的进进进化过程的进化过程的进化过程的进化过程的进化过程的进化过程的进化过程的进化速度。