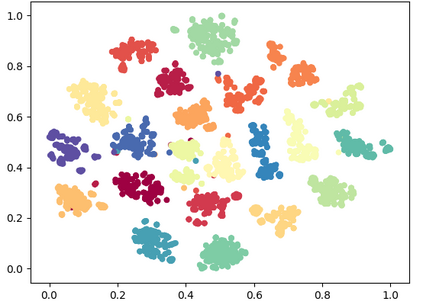
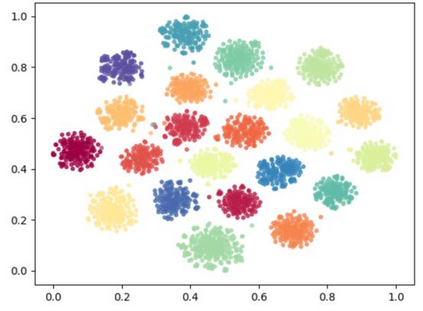
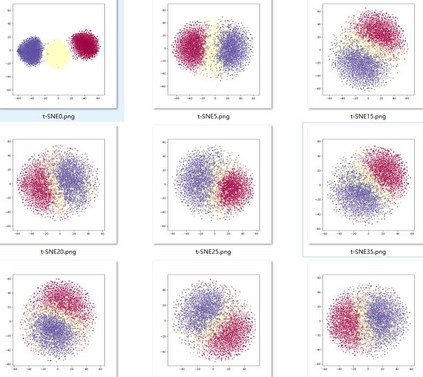
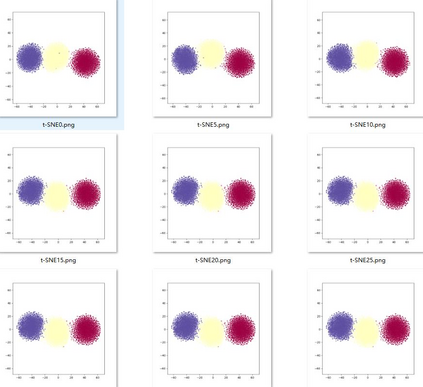
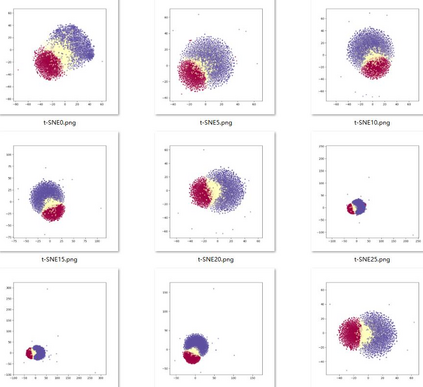
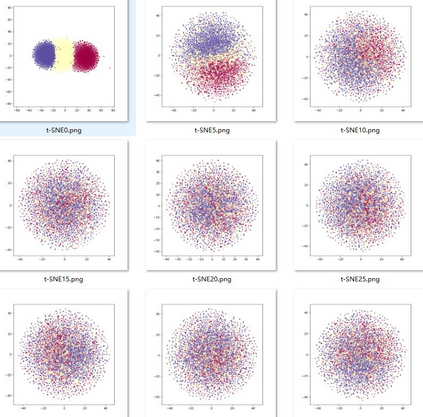
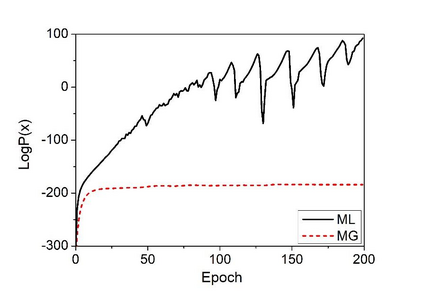
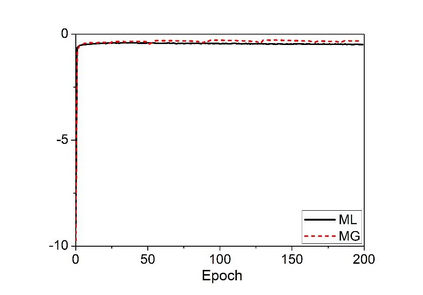
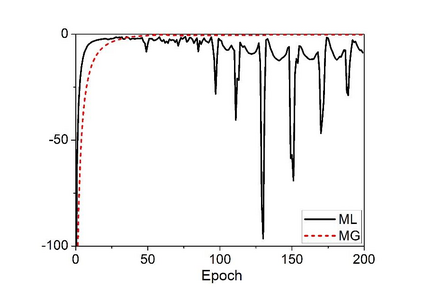
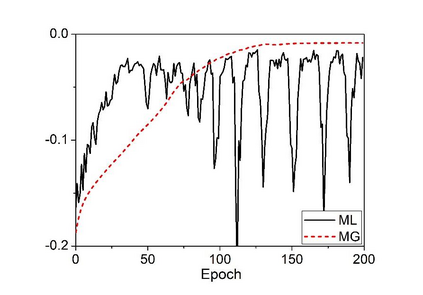
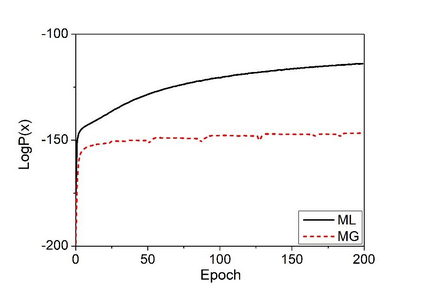
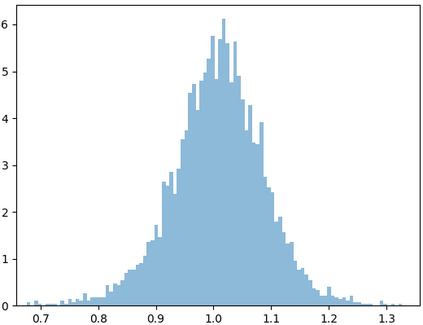
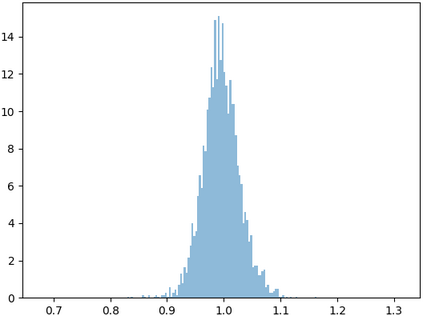
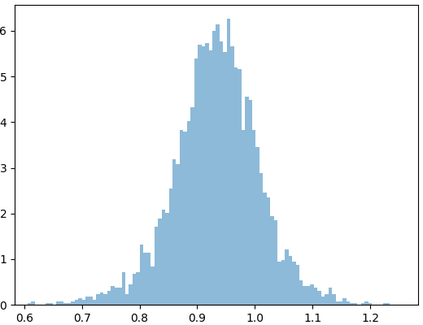
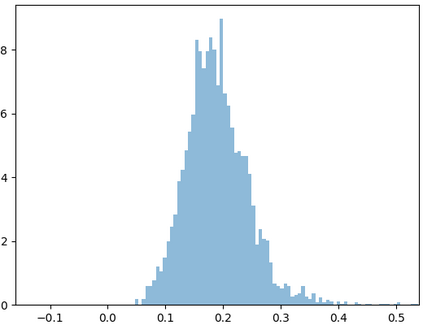
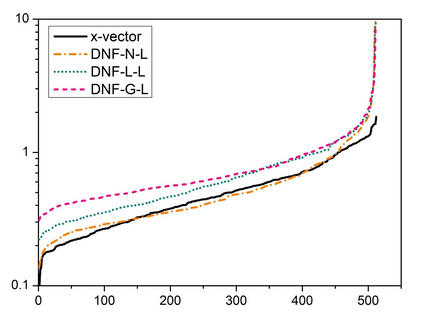
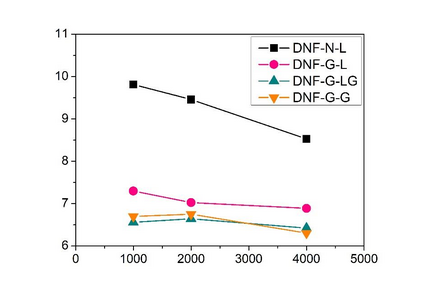
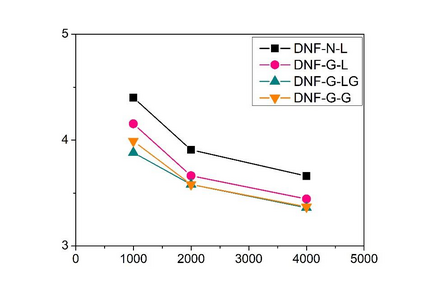
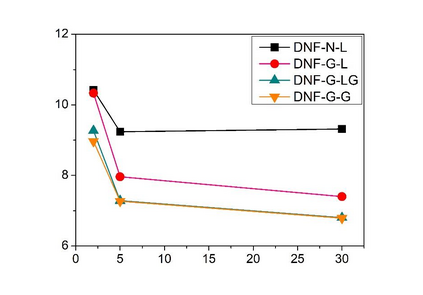
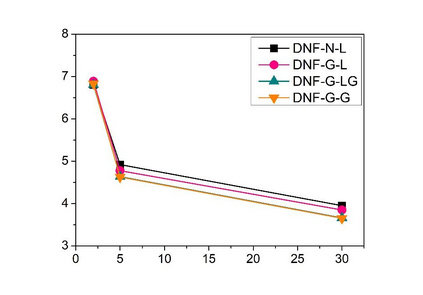
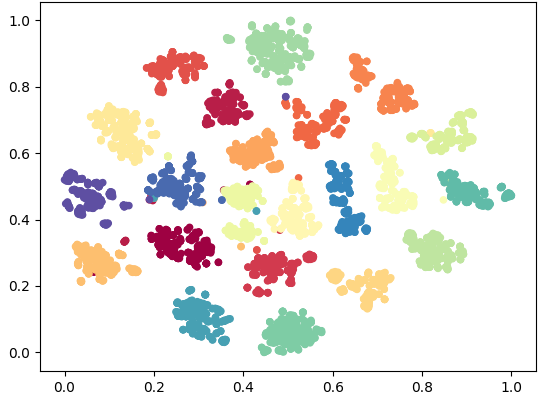
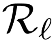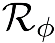Deep speaker embedding represents the state-of-the-art technique for speaker recognition. A key problem with this approach is that the resulting deep speaker vectors tend to be irregularly distributed. In previous research, we proposed a deep normalization approach based on a new discriminative normalization flow (DNF) model, by which the distributions of individual speakers are arguably transformed to homogeneous Gaussians. This normalization was demonstrated to be effective, but despite this remarkable success, we empirically found that the latent codes produced by the DNF model are generally neither homogeneous nor Gaussian, although the model has assumed so. In this paper, we argue that this problem is largely attributed to the maximum-likelihood (ML) training criterion of the DNF model, which aims to maximize the likelihood of the observations but not necessarily improve the Gaussianality of the latent codes. We therefore propose a new Maximum Gaussianality (MG) training approach that directly maximizes the Gaussianality of the latent codes. Our experiments on two data sets, SITW and CNCeleb, demonstrate that our new MG training approach can deliver much better performance than the previous ML training, and exhibits improved domain generalizability, particularly with regard to cosine scoring.
翻译:深层的发言者嵌入代表了最先进的语音识别技术。这个方法的一个关键问题是,由此形成的深层发言者矢量往往不规则地分布。在以前的研究中,我们建议了一种基于新的歧视性正常化流动模式(DNF)的深入正常化办法,根据这种模式,个别发言者的分布可以说已经转化成同质高斯人。这种正常化证明是有效的,但尽管取得了如此显著的成功,但我们从经验中发现,DNF模式产生的潜在代码一般不是同质的,也不是高斯人,尽管模型已经假定了这一点。在本文中,我们认为,这一问题在很大程度上归因于DNF模式的最大相似性(ML)培训标准,目的是最大限度地增加观测的可能性,但不一定改进潜在代码的高斯人性。因此,我们提出了一种新的最大性(MG)培训方法,直接最大限度地提高潜在代码的高斯尼利度。我们在两套数据(SITW和CNCeleb)上的实验表明,我们新的MG培训方法可以提供比以往通用的演示更佳的业绩,特别是改进了通用域。