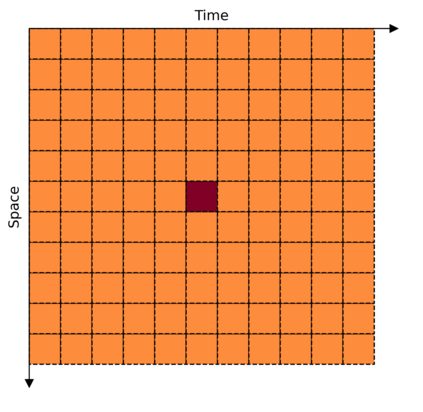
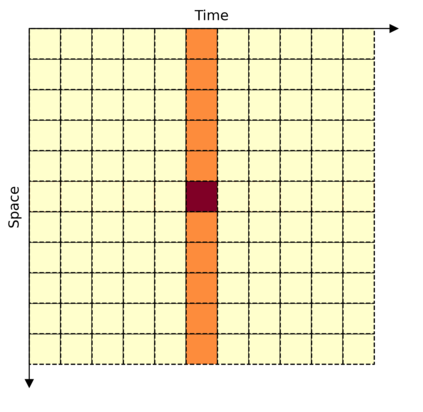
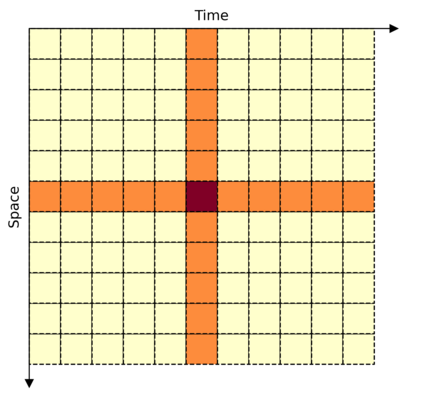
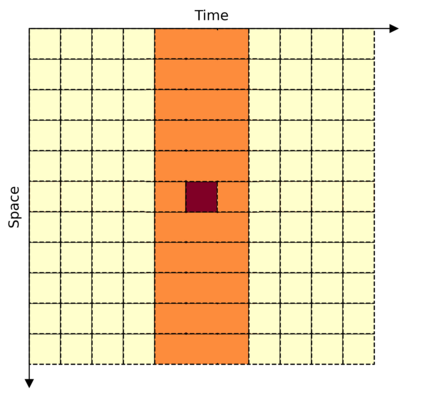
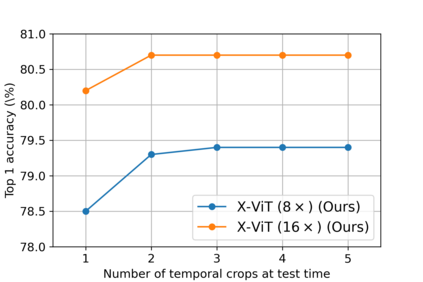
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces \textit{no overhead} compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend \textit{jointly} spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
翻译:本文是在使用变换器的视频识别上。 最近,该领域的尝试在识别准确性方面显示出了令人乐观的结果,但在许多情况中,这些尝试也表明由于对时间信息进行更多的模拟而诱发了重要的计算间接费用。在这项工作中,我们提议了一个视频变换器模型,其复杂性与视频序列中的框架数成线性比例,从而与基于图像的变换器模型相比产生\textit{no subjor}。为了实现这一点,我们的模型对视频变换器中使用的全时关注进行了两次近似接近:(a)它限制了对当地时间窗口的注意,并且利用变换器的深度来获得对视频序列的全面时间覆盖。(b)它使用高效的空间-时间混合来进行视频序列的全时覆盖,而不会在仅以空间为主的注意模型上产生任何额外的成本。为了达到这一目的,我们的模型将两个非常轻的纯度机制结合起来,以最低的计算成本提供额外的准确性改进。我们证明我们的模型在最受欢迎的变换器数据模型上产生了非常高的识别度的准确性,而在其他时间里要成为较高效的变换码。