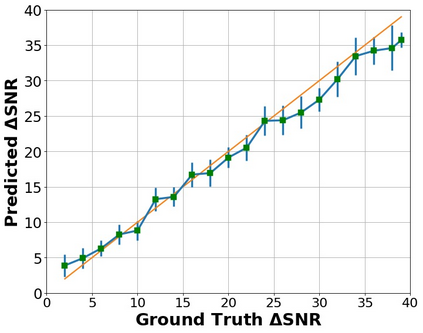
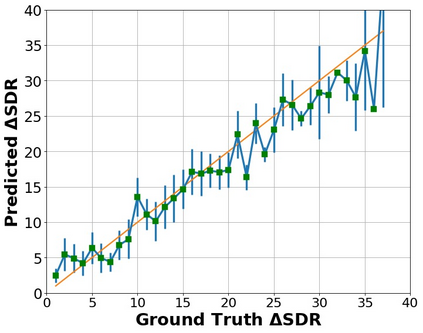
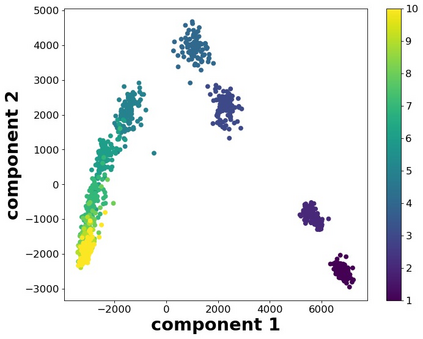
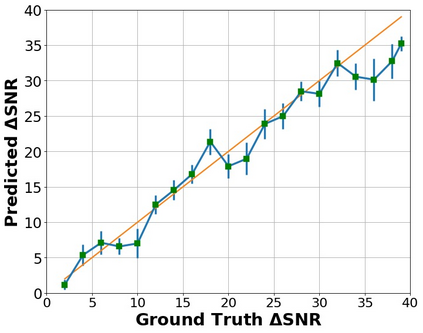
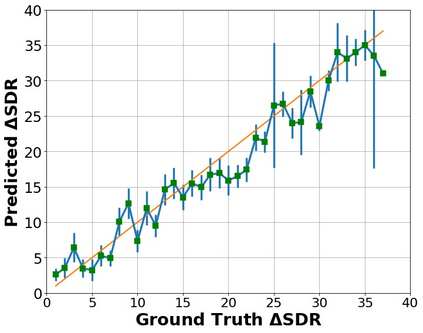
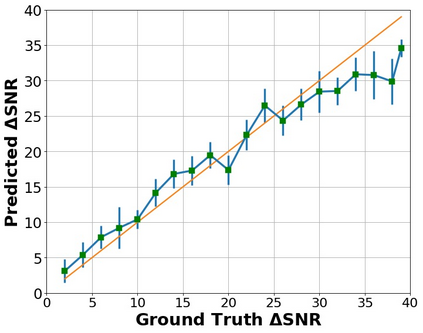
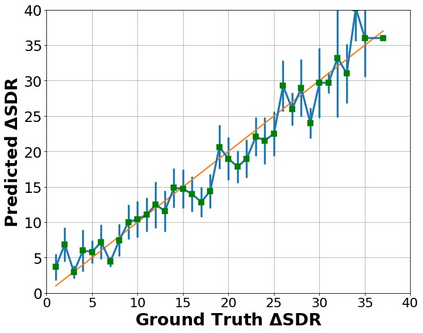
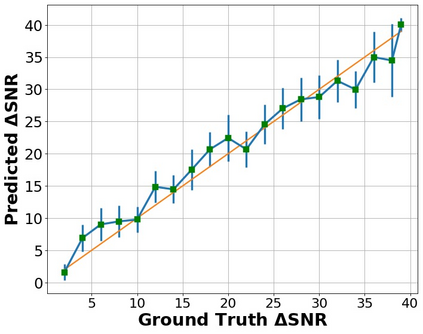
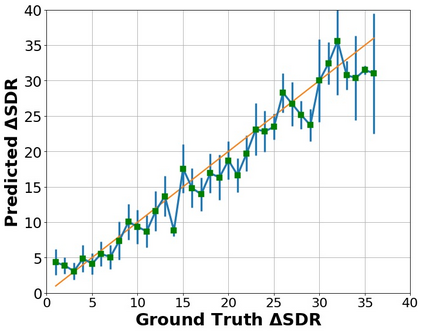
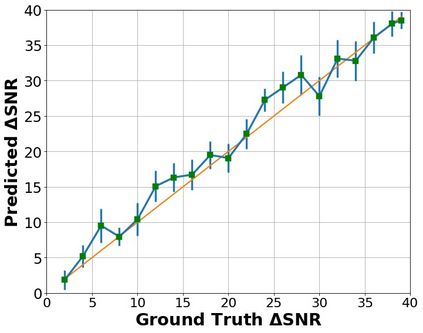
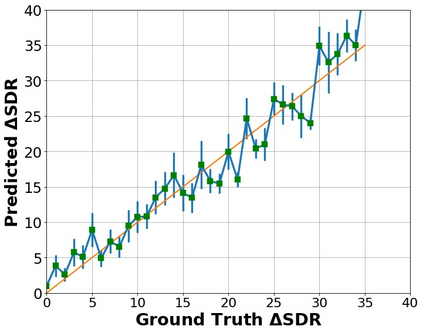
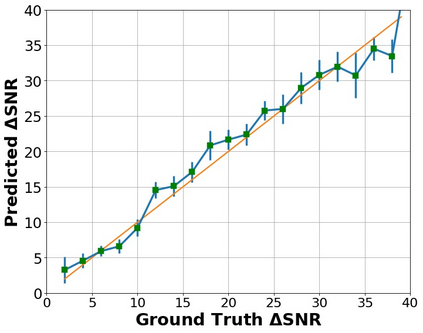
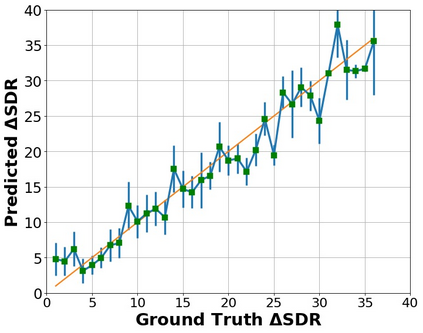
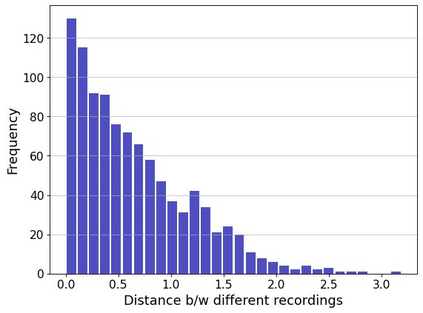
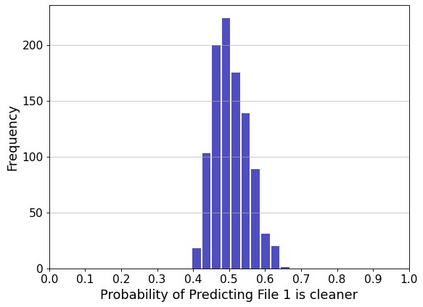
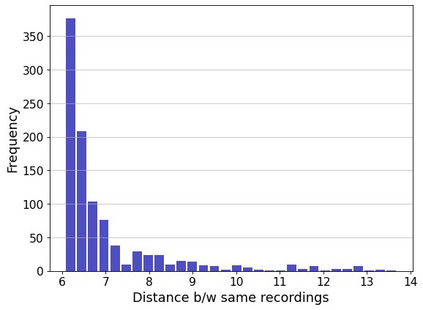
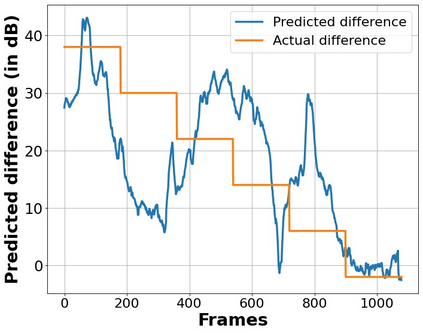
The perceptual task of speech quality assessment (SQA) is a challenging task for machines to do. Objective SQA methods that rely on the availability of the corresponding clean reference have been the primary go-to approaches for SQA. Clearly, these methods fail in real-world scenarios where the ground truth clean references are not available. In recent years, non-intrusive methods that train neural networks to predict ratings or scores have attracted much attention, but they suffer from several shortcomings such as lack of robustness, reliance on labeled data for training and so on. In this work, we propose a new direction for speech quality assessment. Inspired by human's innate ability to compare and assess the quality of speech signals even when they have non-matching contents, we propose a novel framework that predicts a subjective relative quality score for the given speech signal with respect to any provided reference without using any subjective data. We show that neural networks trained using our framework produce scores that correlate well with subjective mean opinion scores (MOS) and are also competitive to methods such as DNSMOS, which explicitly relies on MOS from humans for training networks. Moreover, our method also provides a natural way to embed quality-related information in neural networks, which we show is helpful for downstream tasks such as speech enhancement.
翻译:语言质量评估(SQA)的观念任务对于机器来说是一项艰巨的任务。 依赖相应清洁参考的客观的SQA方法是SQA的主要切入方法。 显然,这些方法在现实世界中在没有地面真相清洁参考的情景中失败。 近年来,培养神经网络以预测评分或得分的非侵入性方法引起了很多注意,但它们存在若干缺陷,如缺乏强健性、在培训时依赖标签数据等等。 在这项工作中,我们提出了语言质量评估的新方向。在人类的内在能力激励下,即使语言信号的内容不匹配,也能够比较和评估其质量。我们提出了一个新的框架,在不使用任何主观数据的情况下,对特定语言信号的主观相对质量进行预测。我们显示,使用我们框架培训的神经网络产生的评分与主观平均评分(MOS)相关,并且对诸如DNSMOS等方法也具有竞争力,因为DNSMOS明确依赖MO系统来比较和评估语言质量,即使其内容不匹配,我们也可以在与神经网络中展示与自然相关的任务。此外,我们所采用的方法也提供了一种与下游质量相关的方法。