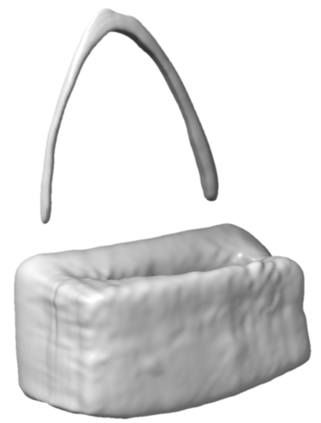
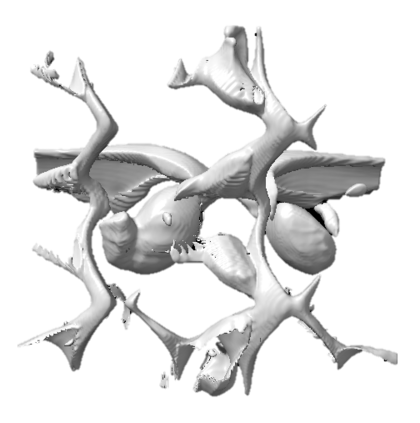Generating accurate 3D models is a challenging problem that traditionally requires explicit learning from 3D datasets using supervised learning. Although recent advances have shown promise in learning 3D models from 2D images, these methods often rely on well-structured datasets with multi-view images of each instance or camera pose information. Furthermore, these datasets usually contain clean backgrounds with simple shapes, making them expensive to acquire and hard to generalize, which limits the applicability of these methods. To overcome these limitations, we propose a method for reconstructing 3D geometry from the diverse and unstructured Imagenet dataset without camera pose information. We use an efficient triplane representation to learn 3D models from 2D images and modify the architecture of the generator backbone based on StyleGAN2 to adapt to the highly diverse dataset. To prevent mode collapse and improve the training stability on diverse data, we propose to use multi-view discrimination. The trained generator can produce class-conditional 3D models as well as renderings from arbitrary viewpoints. The class-conditional generation results demonstrate significant improvement over the current state-of-the-art method. Additionally, using PTI, we can efficiently reconstruct the whole 3D geometry from single-view images.
翻译:暂无翻译