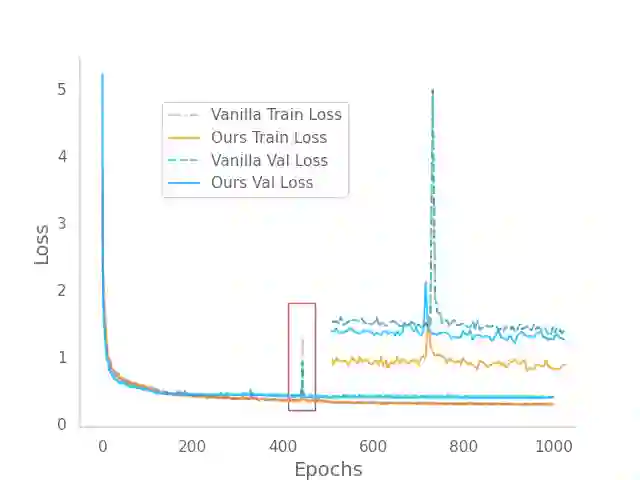
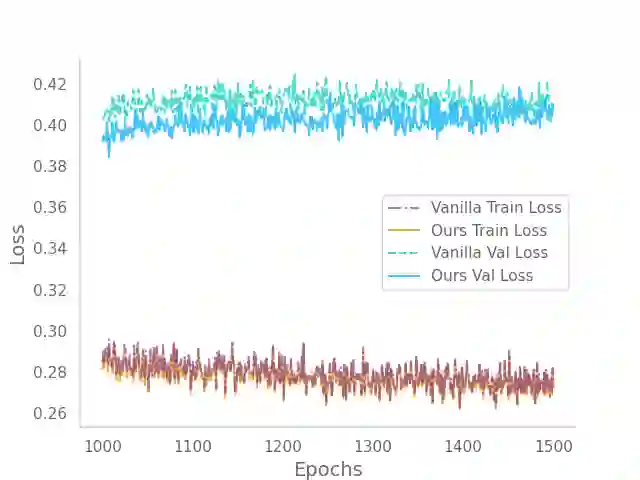
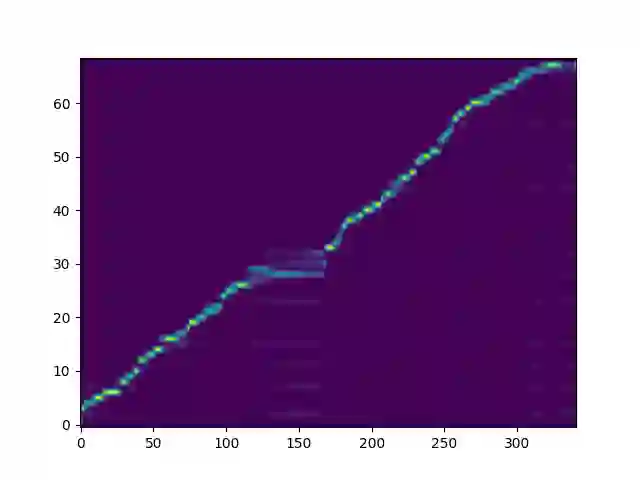
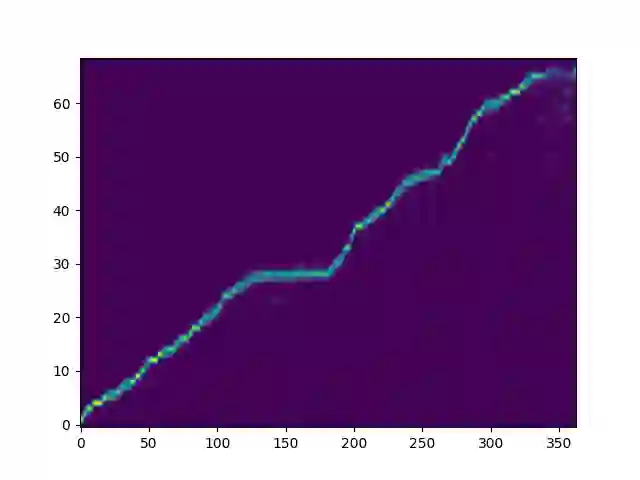
Recent deep learning Text-to-Speech (TTS) systems have achieved impressive performance by generating speech close to human parity. However, they suffer from training stability issues as well as incorrect alignment of the intermediate acoustic representation with the input text sequence. In this work, we introduce Regotron, a regularized version of Tacotron2 which aims to alleviate the training issues and at the same time produce monotonic alignments. Our method augments the vanilla Tacotron2 objective function with an additional term, which penalizes non-monotonic alignments in the location-sensitive attention mechanism. By properly adjusting this regularization term we show that the loss curves become smoother, and at the same time Regotron consistently produces monotonic alignments in unseen examples even at an early stage (13\% of the total number of epochs) of its training process, whereas the fully converged Tacotron2 fails to do so. Moreover, our proposed regularization method has no additional computational overhead, while reducing common TTS mistakes and achieving slighlty improved speech naturalness according to subjective mean opinion scores (MOS) collected from 50 evaluators.
翻译:最近深入学习的文本到语音(TTS)系统取得了令人印象深刻的成绩,产生了接近人文均等的言论。但是,它们受到培训稳定性问题的影响,中间声学表达与输入文本序列的不正确调整。在这项工作中,我们引入了Regotron,这是一个常规版的Tacotron2, 目的是缓解培训问题, 同时产生单声调。我们的方法用一个额外的术语来增强Vanilla Tacotron2的目标功能,这惩罚了对位置敏感关注机制中的非声调一致。我们通过适当调整这个正规化术语,我们发现损失曲线变得更加平滑,同时Regotron甚至在培训过程的早期阶段( 占总教区总数13 % ), 也始终在无法在未见的事例中产生单声调, 而完全趋同的Tacotron2 却未能做到这一点。 此外,我们提议的规范化方法没有额外的计算间接费用,同时减少常见的TTS错误,并实现slighlty的语音自然性,根据50评价员的主观平均意见分数(MOS) 。