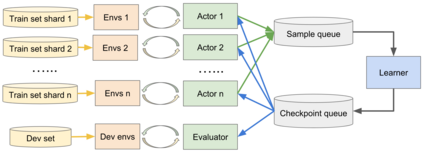
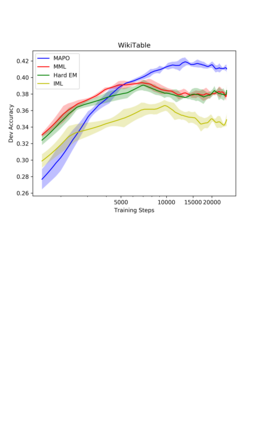
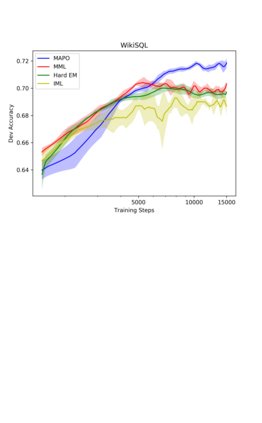
This paper presents Memory Augmented Policy Optimization (MAPO): a novel policy optimization formulation that incorporates a memory buffer of promising trajectories to reduce the variance of policy gradient estimates for deterministic environments with discrete actions. The formulation expresses the expected return objective as a weighted sum of two terms: an expectation over a memory of trajectories with high rewards, and a separate expectation over the trajectories outside the memory. We propose 3 techniques to make an efficient training algorithm for MAPO: (1) distributed sampling from inside and outside memory with an actor-learner architecture; (2) a marginal likelihood constraint over the memory to accelerate training; (3) systematic exploration to discover high reward trajectories. MAPO improves the sample efficiency and robustness of policy gradient, especially on tasks with a sparse reward. We evaluate MAPO on weakly supervised program synthesis from natural language / semantic parsing tasks. On the WikiTableQuestions benchmark we improve the state-of-the-art by 2.5%, achieving an accuracy of 46.2%, and on the WikiSQL benchmark, MAPO achieves an accuracy of 74.9% with only weak supervision, outperforming several strong baselines with full supervision. Our code is open sourced at https://github.com/crazydonkey200/neural-symbolic-machines
翻译:本文介绍了记忆增强政策优化(MAPO):一种新的政策优化方案,其中包含了充满希望的轨迹的记忆缓冲,以降低政策梯度估计对确定环境的偏差,同时采取分立行动。该案文表示预期返回目标,是两个条件的加权总和:对具有高回报的轨迹的记忆的期待,以及对记忆外轨迹的单独期望。我们提议了3种技术,为MAPO提供一种有效的培训算法:(1) 以一个行为者-利纳结构从内部和外部分发记忆样本;(2) 对记忆的边缘可能性加以限制,以加速培训;(3) 系统探索,以发现高奖励轨迹。MAPO提高了政策梯度的样本效率和稳健性,特别是在微微的奖励任务上。我们评价MAPO对自然语言/语系定分立任务中监管不力的组合程序。关于Wiki 表问题的基准,我们改进了状态-艺术的2.5 %,实现了46.2%的精确度,以及WikS-QL基准, MAPOs在数个强的标码上,只有74.9%/MAPOI/ASy crudeal b trup pral brucal spral suply suply suplypral suplypralpral spralpralpralpralpral supalpral spral supal supalps.