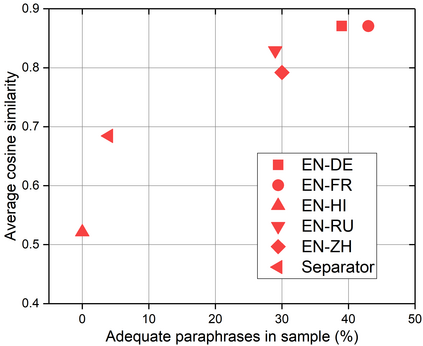
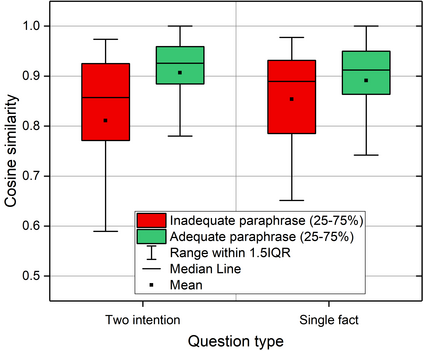
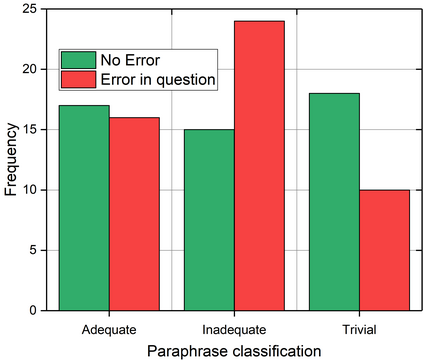
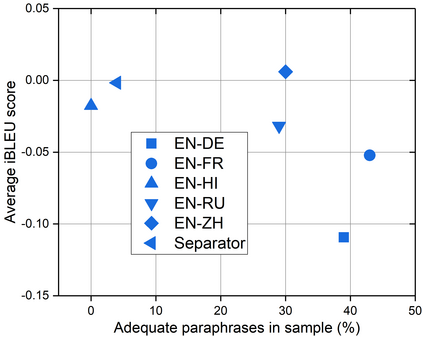
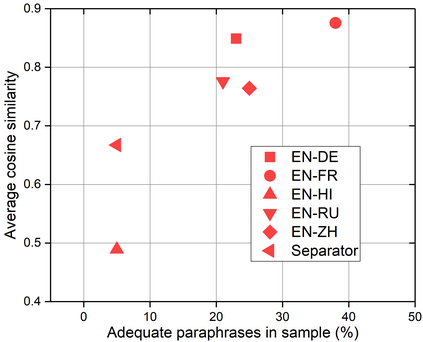
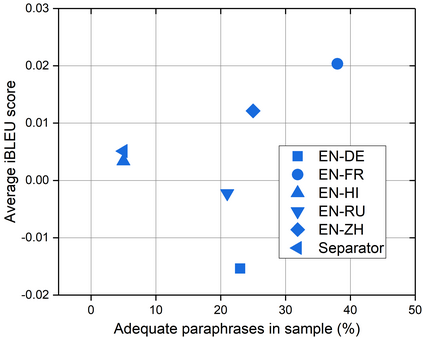
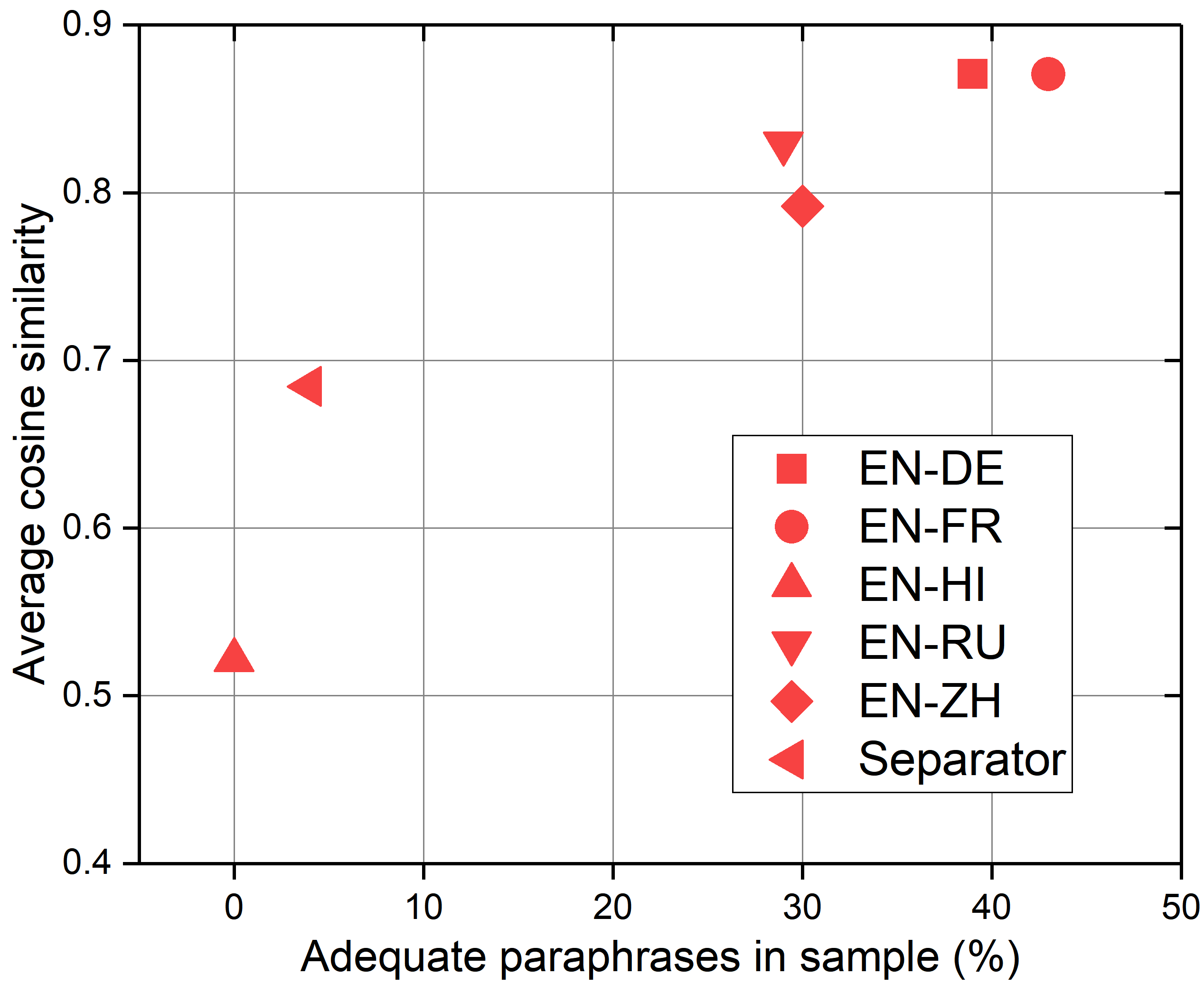
We present a study into the ability of paraphrase generation methods to increase the variety of natural language questions that the FRANK Question Answering system can answer. We first evaluate paraphrase generation methods on the LC-QuAD 2.0 dataset using both automatic metrics and human judgement, and discuss their correlation. Error analysis on the dataset is also performed using both automatic and manual approaches, and we discuss how paraphrase generation and evaluation is affected by data points which contain error. We then simulate an implementation of the best performing paraphrase generation method (an English-French backtranslation) into FRANK in order to test our original hypothesis, using a small challenge dataset. Our two main conclusions are that cleaning of LC-QuAD 2.0 is required as the errors present can affect evaluation; and that, due to limitations of FRANK's parser, paraphrase generation is not a method which we can rely on to improve the variety of natural language questions that FRANK can answer.
翻译:我们提出对参数生成方法的能力的研究,以增加FRANK问题解答系统可以回答的自然语言问题的多样性。 我们首先使用自动计量和人文判断来评估LC-QAD2.0数据集的参数生成方法,并讨论其相关性。 对数据集的错误分析也同时使用自动和人工方法进行,我们讨论参数生成和评价如何受到包含错误的数据点的影响。 然后我们模拟将最佳的参数生成方法(英法回译)应用到FRANK, 以测试我们最初的假设, 使用一个小挑战数据集。 我们的两个主要结论是, 需要清理 LC- QUAD 2.0, 因为目前的错误会影响评价; 由于FRANK的解析器的局限性, 我们无法依赖这些参数生成方法来改进FRANK能够回答的自然语言问题的多样性 。