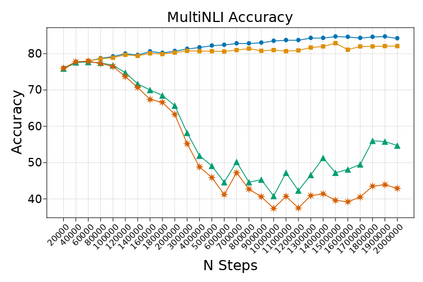
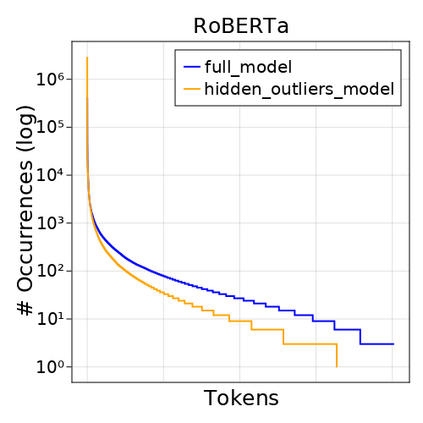
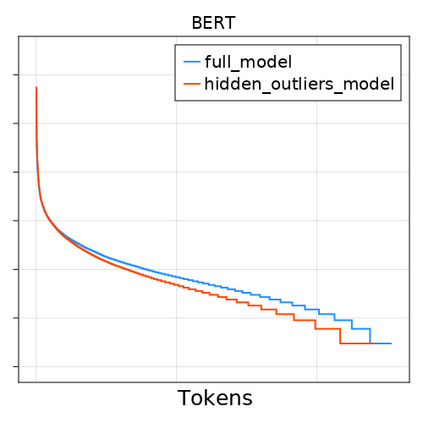
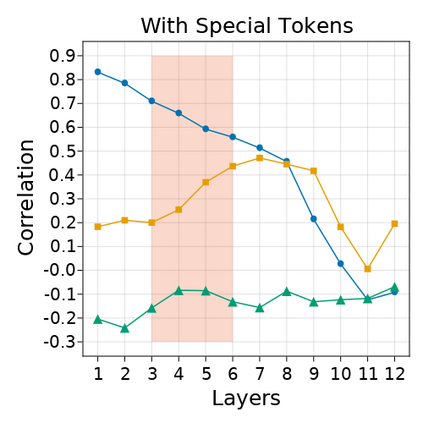
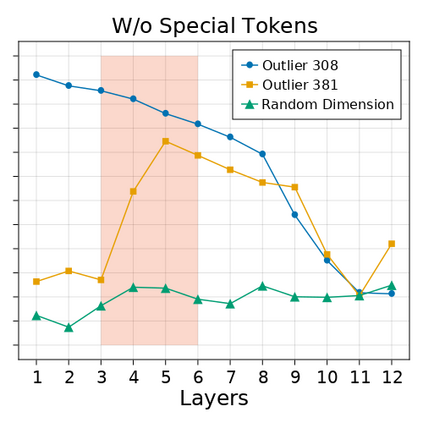
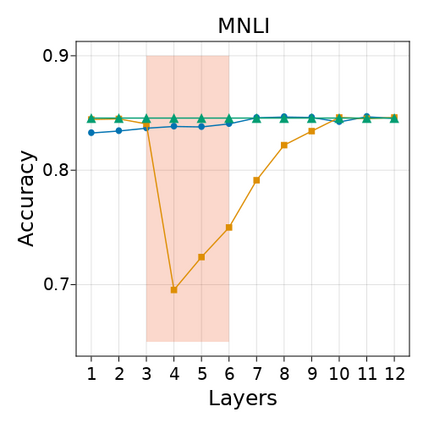
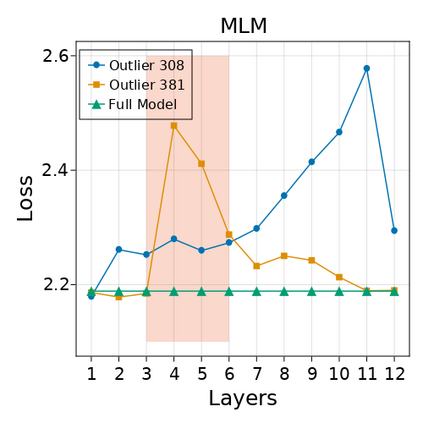
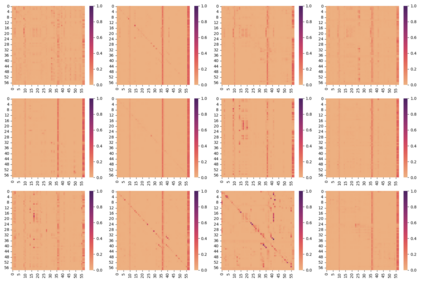
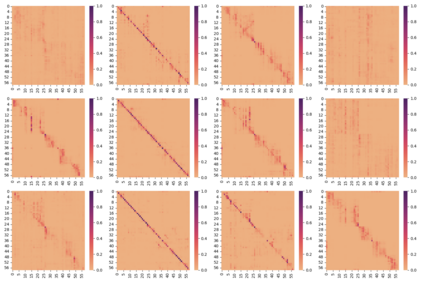
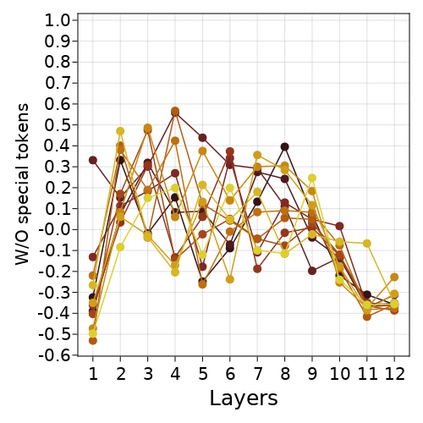
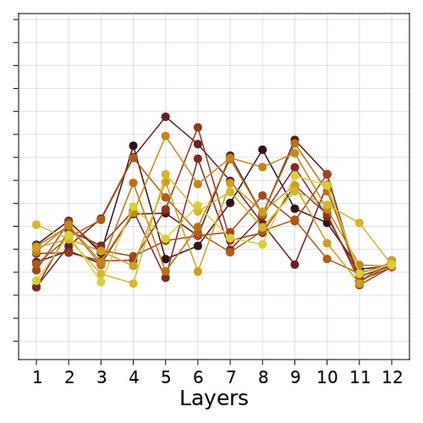
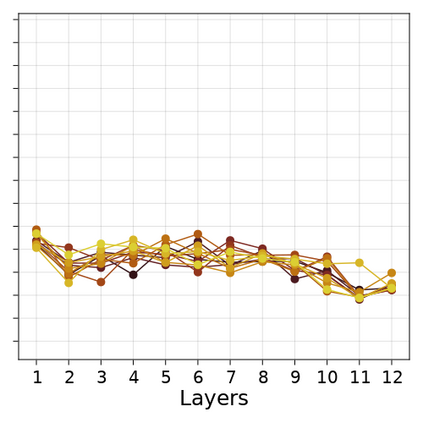
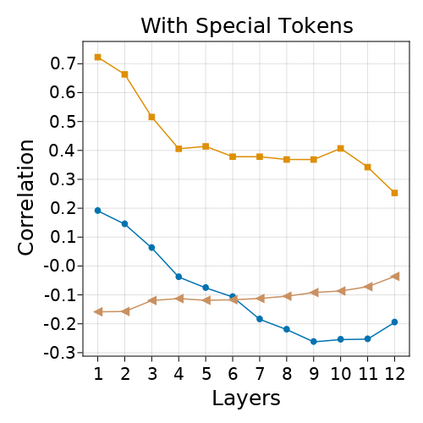
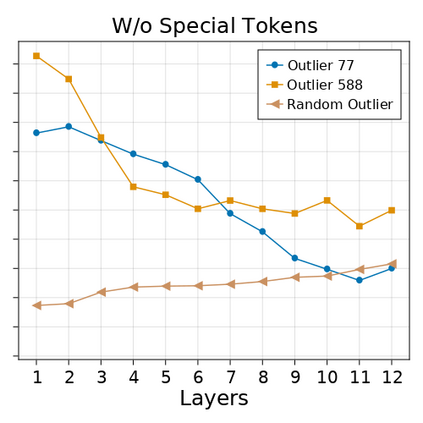
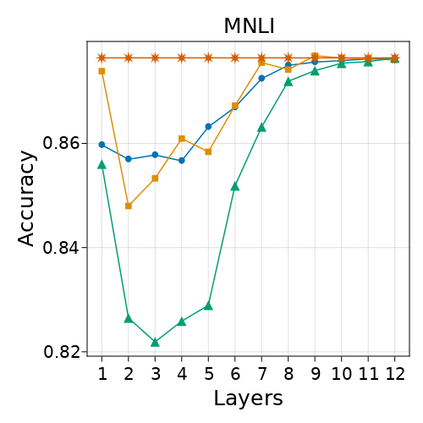
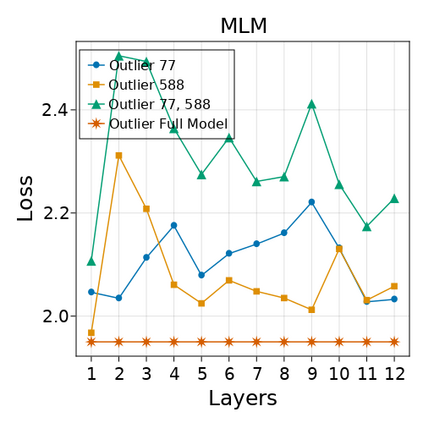
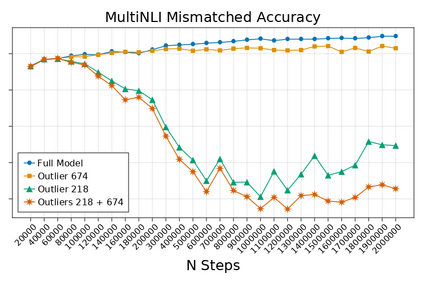
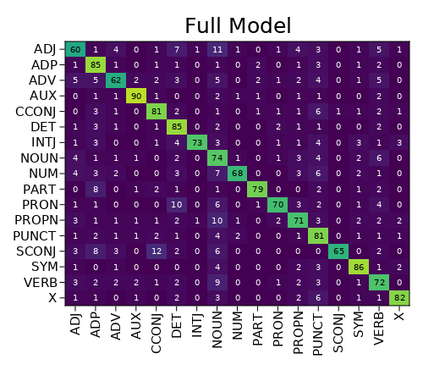
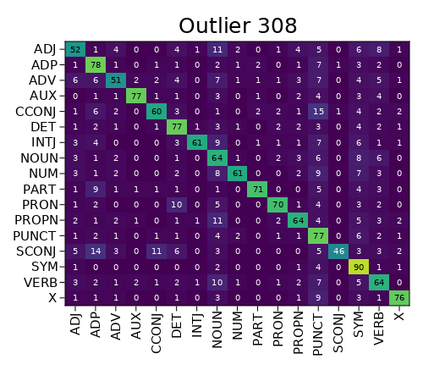
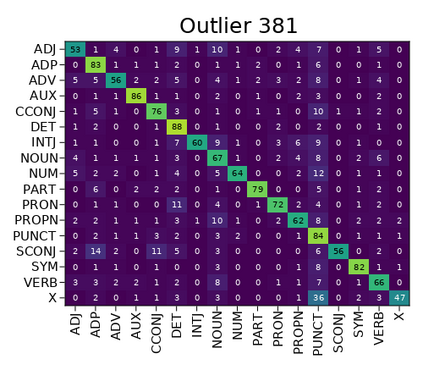
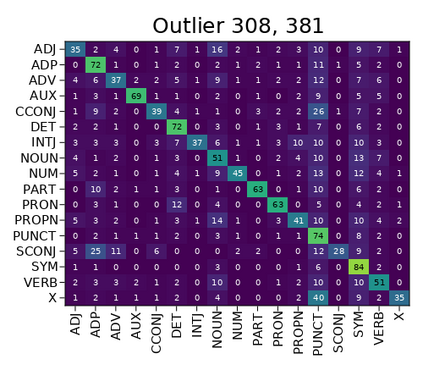
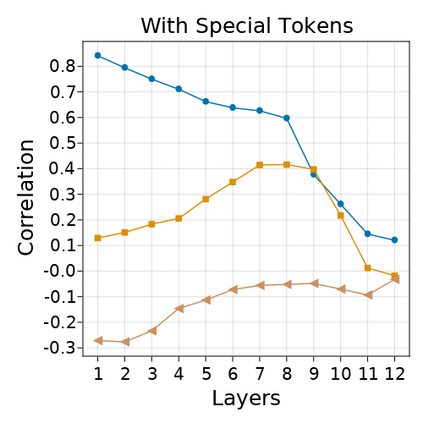
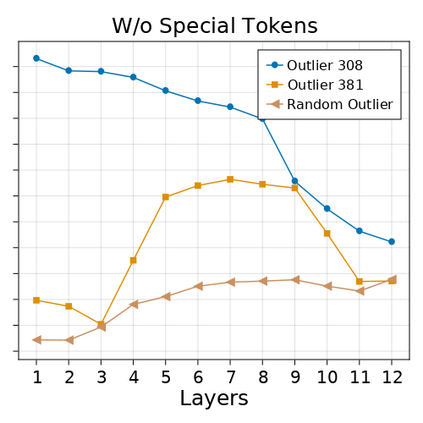
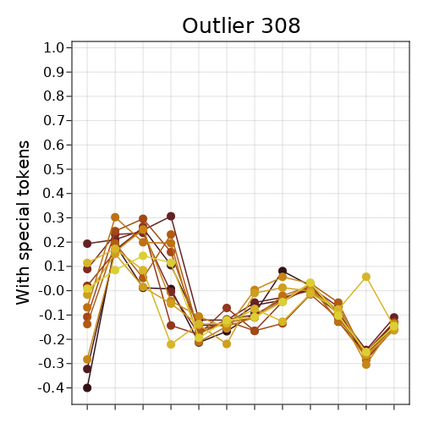
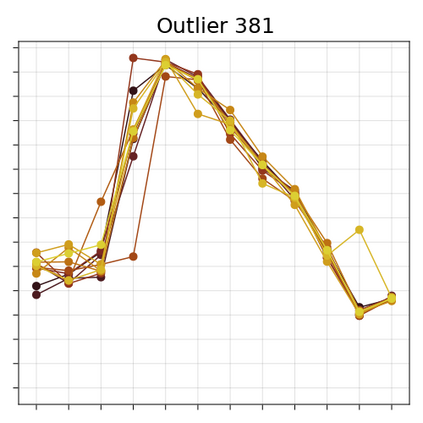
Transformer-based language models are known to display anisotropic behavior: the token embeddings are not homogeneously spread in space, but rather accumulate along certain directions. A related recent finding is the outlier phenomenon: the parameters in the final element of Transformer layers that consistently have unusual magnitude in the same dimension across the model, and significantly degrade its performance if disabled. We replicate the evidence for the outlier phenomenon and we link it to the geometry of the embedding space. Our main finding is that in both BERT and RoBERTa the token frequency, known to contribute to anisotropicity, also contributes to the outlier phenomenon. In its turn, the outlier phenomenon contributes to the "vertical" self-attention pattern that enables the model to focus on the special tokens. We also find that, surprisingly, the outlier effect on the model performance varies by layer, and that variance is also related to the correlation between outlier magnitude and encoded token frequency.
翻译:以变异器为基础的语言模型可以显示厌食行为:象征性嵌入在空间中不是单一的分布,而是沿着某些方向积累。最近的一个相关发现是外生现象:变异器层最后元素的参数在整个模型中始终具有非同寻常的大小,如果禁用,则其性能会大大降低。我们复制外生现象的证据,并将它与嵌入空间的几何学联系起来。我们的主要发现是,在BERT 和 RoBERTA这两个已知有助于厌食的象征频率中,象征性频率也促成了外生现象。归根结底,外生现象促成了“垂直”自我注意模式的图案,使模型能够聚焦于特殊符号。我们还发现,令人惊讶的是,模型性能的外生效应因层而异,而且差异也与外生量与编码符号频率的相关性有关。