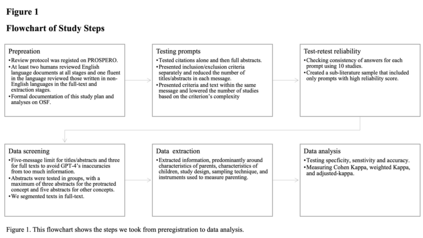
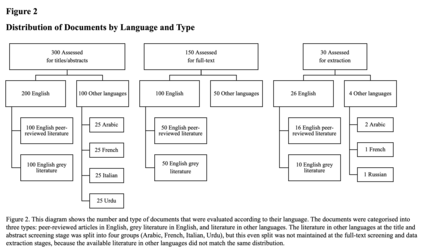
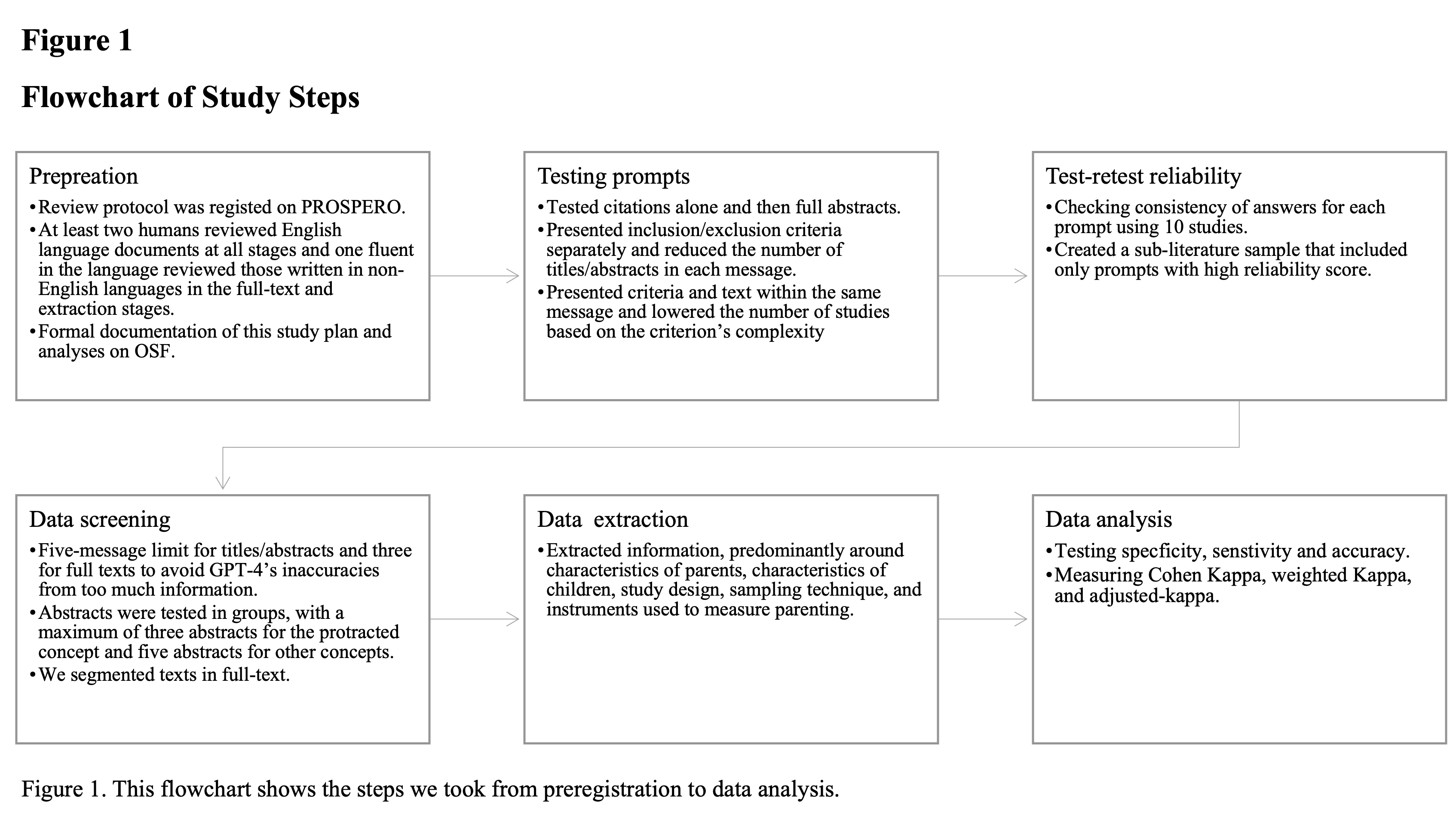
Systematic reviews are vital for guiding practice, research, and policy, yet they are often slow and labour-intensive. Large language models (LLMs) could offer a way to speed up and automate systematic reviews, but their performance in such tasks has not been comprehensively evaluated against humans, and no study has tested GPT-4, the biggest LLM so far. This pre-registered study evaluates GPT-4's capability in title/abstract screening, full-text review, and data extraction across various literature types and languages using a 'human-out-of-the-loop' approach. Although GPT-4 had accuracy on par with human performance in most tasks, results were skewed by chance agreement and dataset imbalance. After adjusting for these, there was a moderate level of performance for data extraction, and - barring studies that used highly reliable prompts - screening performance levelled at none to moderate for different stages and languages. When screening full-text literature using highly reliable prompts, GPT-4's performance was 'almost perfect.' Penalising GPT-4 for missing key studies using highly reliable prompts improved its performance even more. Our findings indicate that, currently, substantial caution should be used if LLMs are being used to conduct systematic reviews, but suggest that, for certain systematic review tasks delivered under reliable prompts, LLMs can rival human performance.
翻译:暂无翻译