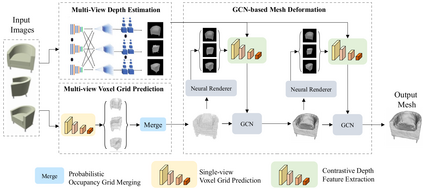
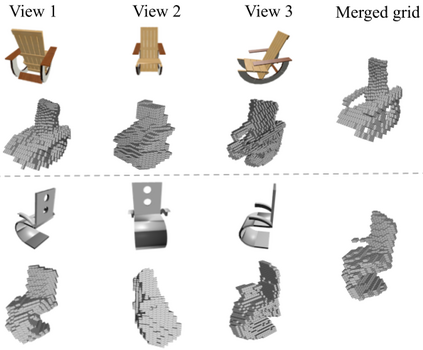
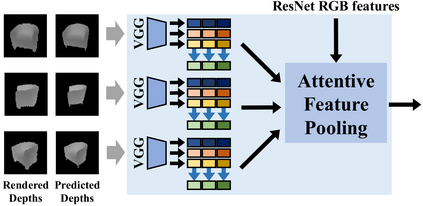
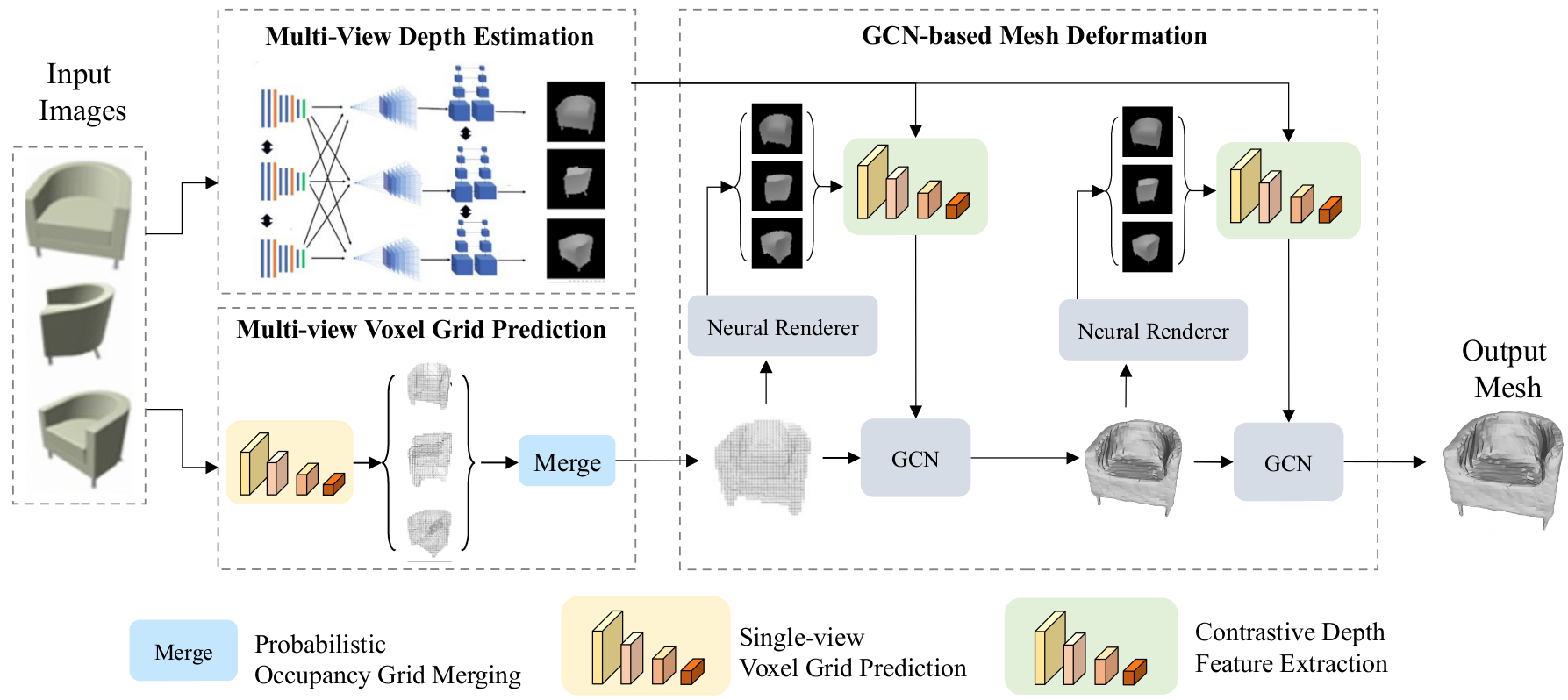
Deep learning based 3D shape generation methods generally utilize latent features extracted from color images to encode the semantics of objects and guide the shape generation process. These color image semantics only implicitly encode 3D information, potentially limiting the accuracy of the generated shapes. In this paper we propose a multi-view mesh generation method which incorporates geometry information explicitly by using the features from intermediate depth representations of multi-view stereo and regularizing the 3D shapes against these depth images. First, our system predicts a coarse 3D volume from the color images by probabilistically merging voxel occupancy grids from the prediction of individual views. Then the depth images from multi-view stereo along with the rendered depth images of the coarse shape are used as a contrastive input whose features guide the refinement of the coarse shape through a series of graph convolution networks. Notably, we achieve superior results than state-of-the-art multi-view shape generation methods with 34% decrease in Chamfer distance to ground truth and 14% increase in F1-score on ShapeNet dataset.Our source code is available at \url{https://git.io/Jmalg}
翻译:基于 3D 的深层学习形状生成方法通常使用从彩色图像中提取的隐性特征来编码对象的语义,并引导形状生成过程。这些彩色图像语义只隐含地编码 3D 信息,有可能限制生成形状的准确性。在本文中,我们建议一种多视图网状生成方法,通过使用多视图立体的中间深度显示特征,明确纳入几何信息,并根据这些深度图像对3D 形状进行常规化。首先,我们的系统通过将单个视图预测的 voxel 占用网进行概率性合并,从颜色图像中预测出一个粗略的 3D 体积。然后,多视图立体的深度图像以及粗形的深度图像被用作对比性输入,其特征引导着通过一系列图象卷流网络对粗形形状的完善。值得注意的是,我们取得了优异的结果,而Chamfer 到地面的距离减少了34%, ShapeNet 数据设置的F1-score增加了14%。我们的源代码可以在\ http://gigio@ gio.