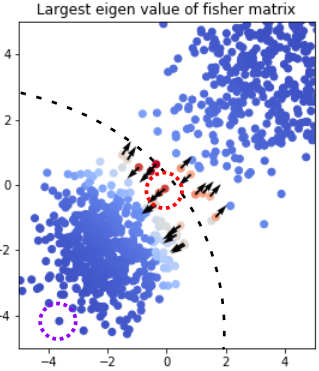
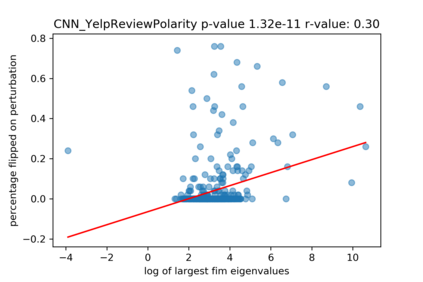
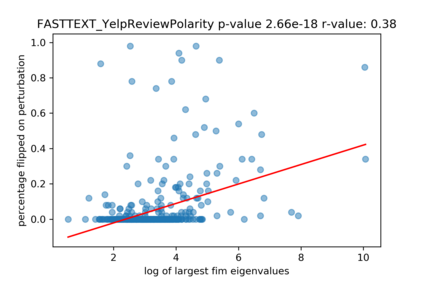
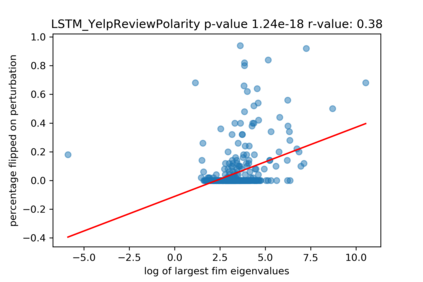
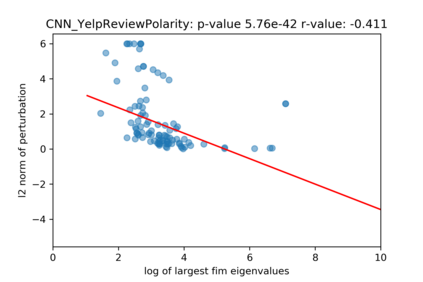
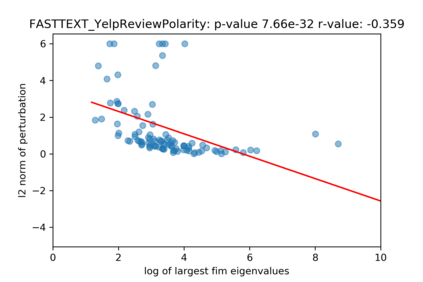
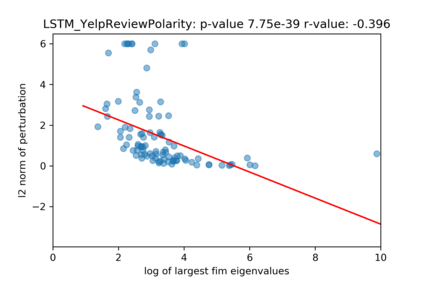
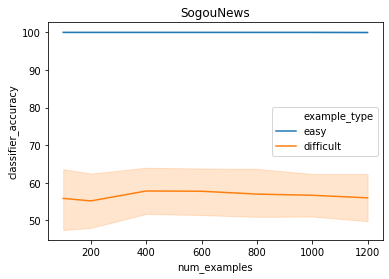
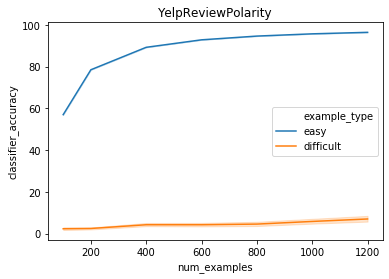
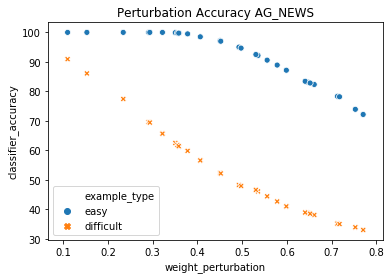
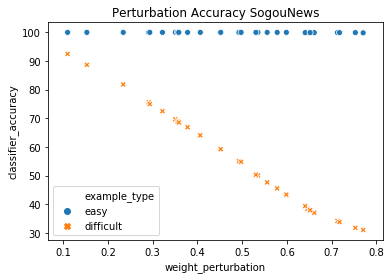
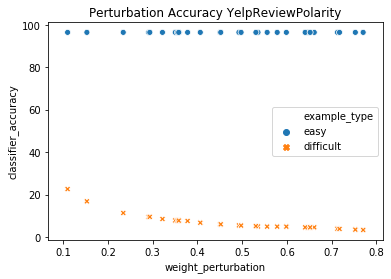
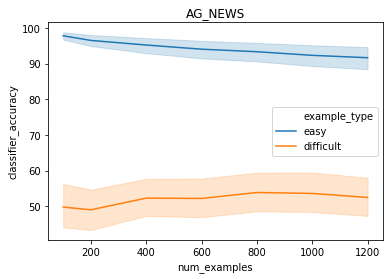
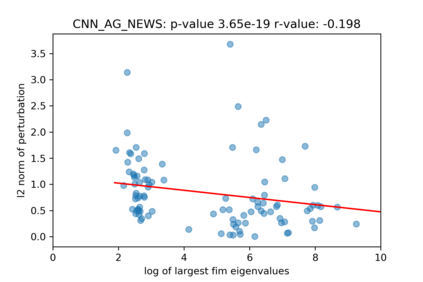
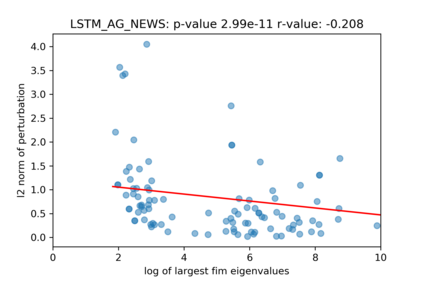
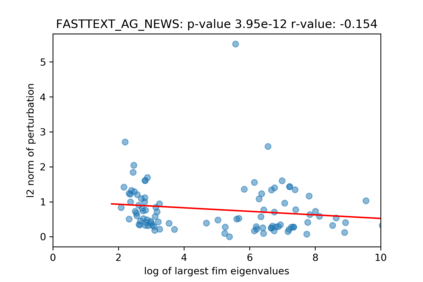
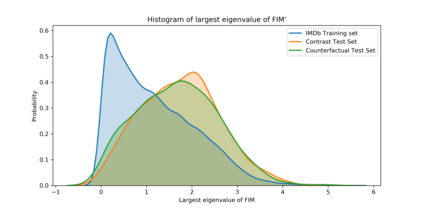
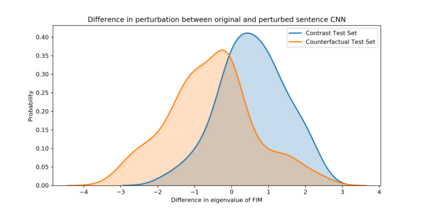
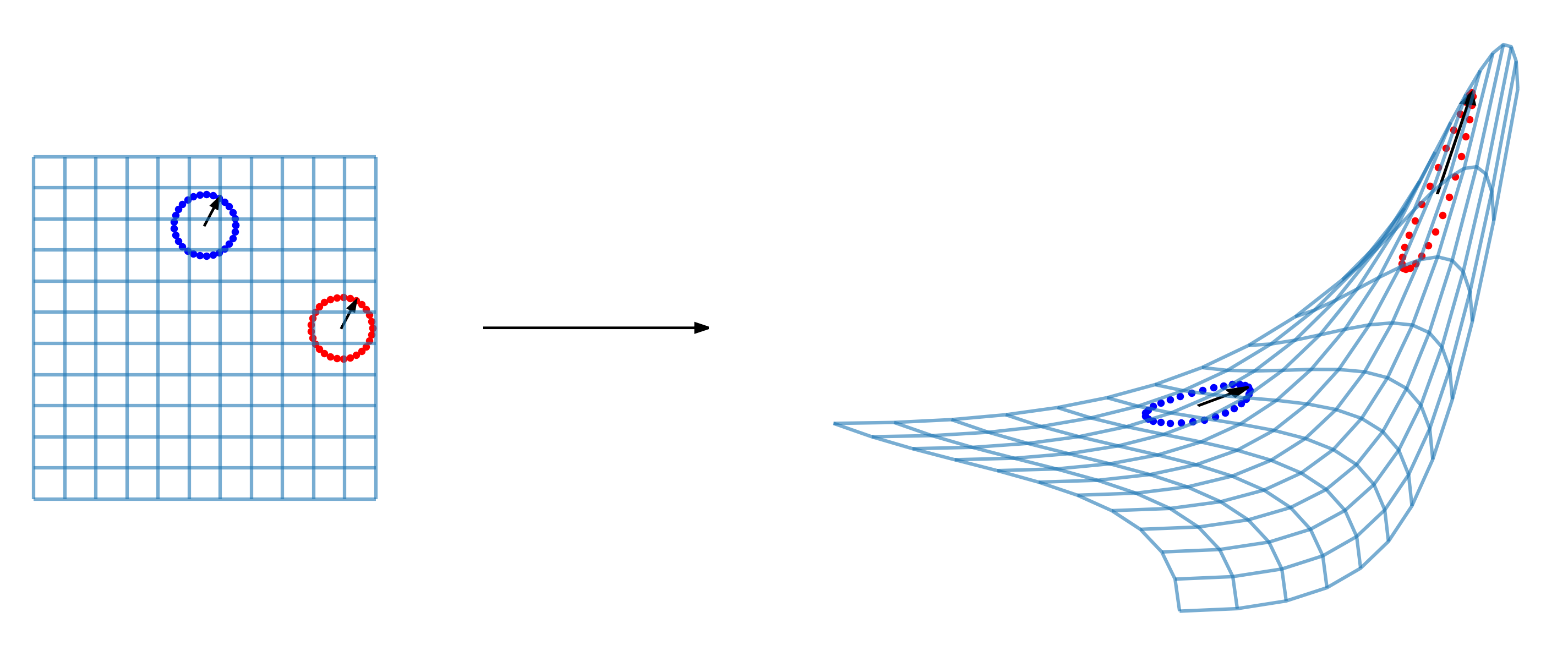
A growing body of recent evidence has highlighted the limitations of natural language processing (NLP) datasets and classifiers. These include the presence of annotation artifacts in datasets, classifiers relying on shallow features like a single word (e.g., if a movie review has the word "romantic", the review tends to be positive), or unnecessary words (e.g., learning a proper noun to classify a movie as positive or negative). The presence of such artifacts has subsequently led to the development of challenging datasets to force the model to generalize better. While a variety of heuristic strategies, such as counterfactual examples and contrast sets, have been proposed, the theoretical justification about what makes these examples difficult for the classifier is often lacking or unclear. In this paper, using tools from information geometry, we propose a theoretical way to quantify the difficulty of an example in NLP. Using our approach, we explore difficult examples for several deep learning architectures. We discover that both BERT, CNN and fasttext are susceptible to word substitutions in high difficulty examples. These classifiers tend to perform poorly on the FIM test set. (generated by sampling and perturbing difficult examples, with accuracy dropping below 50%). We replicate our experiments on 5 NLP datasets (YelpReviewPolarity, AGNEWS, SogouNews, YelpReviewFull and Yahoo Answers). On YelpReviewPolarity we observe a correlation coefficient of -0.4 between resilience to perturbations and the difficulty score. Similarly we observe a correlation of 0.35 between the difficulty score and the empirical success probability of random substitutions. Our approach is simple, architecture agnostic and can be used to study the fragilities of text classification models. All the code used will be made publicly available, including a tool to explore the difficult examples for other datasets.
翻译:最近越来越多的大量证据突显了自然语言处理(NLP)数据集和分类的局限性,其中包括:在数据集中存在批注手工艺品;依赖像单词这样的浅质特征的分类师(例如,如果电影审查有“浪漫”一词,审查往往是正面的),或不必要的单词(例如,学习一个适当的名词,将电影归类为正或负)的局限性。这些工艺品的存在随后导致开发了具有挑战性的数据集,迫使模型更好地概括化。虽然提出了各种超常策略,例如反事实示例和对比组等,但关于使分类员难于这些特征的理论解释往往缺乏或不清楚。在本文中,使用信息地理测量工具来量化NLP的例子的难度。使用我们的方法,我们为一些深层次学习结构探索困难的例子。我们发现,BERT、CNNM和快速文本都容易在高难度示例中进行词替换。这些分类师往往在FTeral Veral Veriab 中进行低调的精确度测试。