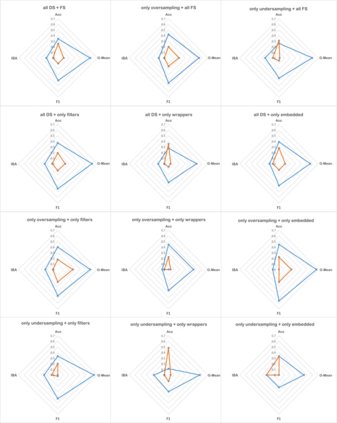
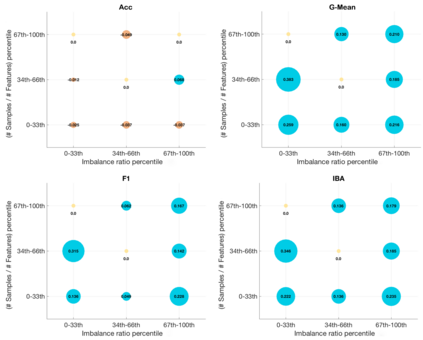
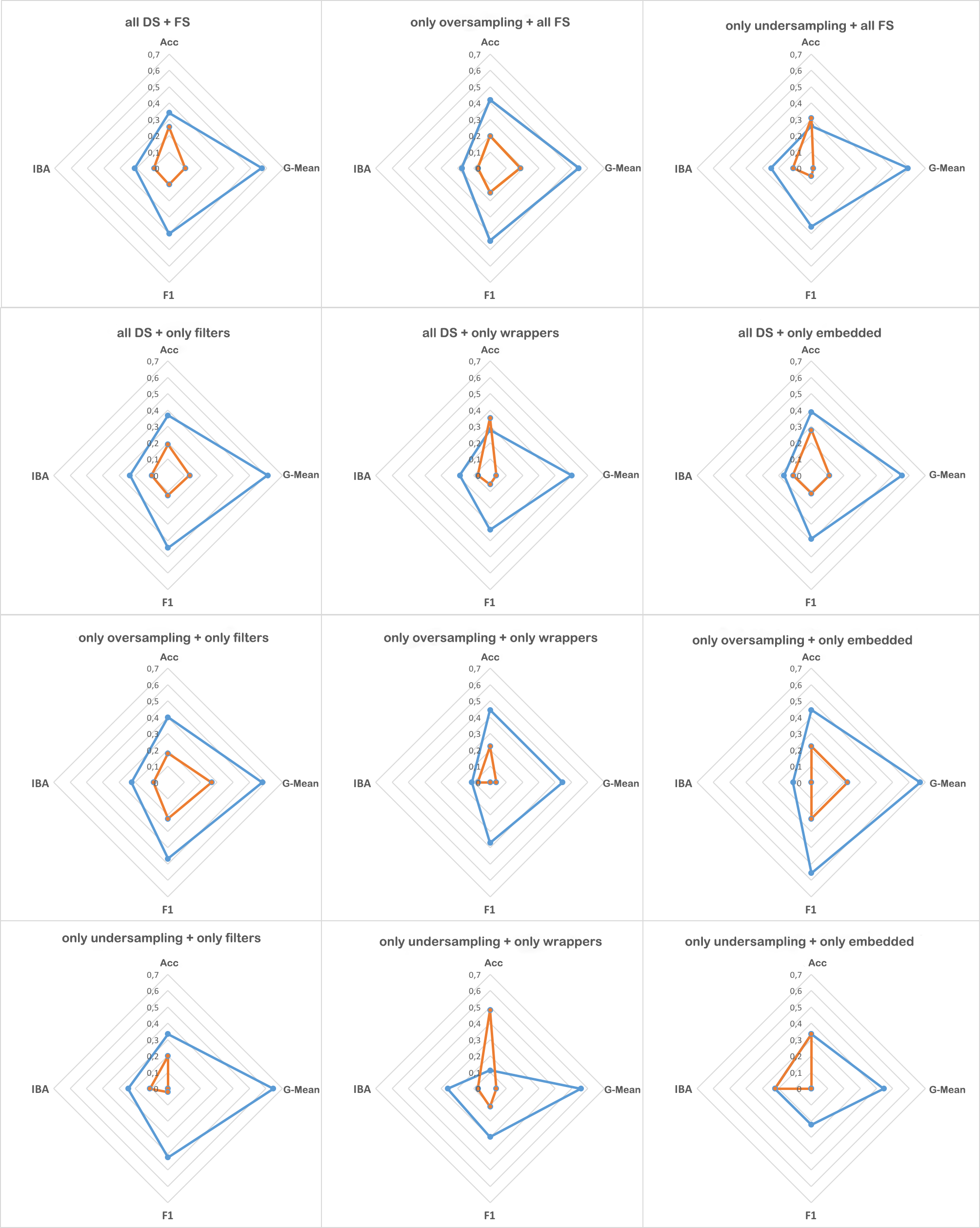
In predictive tasks, real-world datasets often present different degrees of imbalanced (i.e., long-tailed or skewed) distributions. While the majority (the head) classes have sufficient samples, the minority (the tail) classes can be under-represented by a rather limited number of samples. Data pre-processing has been shown to be very effective in dealing with such problems. On one hand, data re-sampling is a common approach to tackling class imbalance. On the other hand, dimension reduction, which reduces the feature space, is a conventional technique for reducing noise and inconsistencies in a dataset. However, the possible synergy between feature selection and data re-sampling for high-performance imbalance classification has rarely been investigated before. To address this issue, we carry out a comprehensive empirical study on the joint influence of feature selection and re-sampling on two-class imbalance classification. Specifically, we study the performance of two opposite pipelines for imbalance classification by applying feature selection before or after data re-sampling. We conduct a large number of experiments, with a total of 9225 tests, on 52 publicly available datasets, using 9 feature selection methods, 6 re-sampling approaches for class imbalance learning, and 3 well-known classification algorithms. Experimental results show that there is no constant winner between the two pipelines; thus both of them should be considered to derive the best performing model for imbalance classification. We find that the performance of an imbalance classification model not only depends on the classifier adopted and the ratio between the number of majority and minority samples, but also depends on the ratio between the number of samples and features. Overall, this study should provide new reference value for researchers and practitioners in imbalance learning.
翻译:在预测性任务中,真实世界数据集往往呈现出不同程度的不平衡分布(即长尾或偏斜)分布。虽然多数(头)类具有足够的样本,但少数(尾)类可能代表不足,因为抽样数量有限。数据预处理显示在处理这类问题方面非常有效。一方面,数据再抽样是解决阶级不平衡的一种常见办法。另一方面,减少比例减少,减少了特征空间,是减少数据集噪音和不一致的常规技术。然而,虽然大多数(头)类的特征选择和重新采样用于高绩效不平衡分类的数据样本之间可能存在的协同效应,但以前很少调查过少数(尾)类(尾)类别。为了解决这一问题,我们开展了一项关于特征选择和再采样对二类不平衡分类的共同影响的全面实证研究。具体地说,我们通过在数据重新采样之前或之后采用特征选择模式来研究不平衡分类的两条渠道的绩效。我们进行了大量实验,总共进行了9225次的测试,在52个公开的深度选择中,用9种模型选择方法来进行绩效分类。因此,我们应先行两种方法来进行。我们研究,然后再研究,然后再研究。我们再研究两种方法来再研究,然后再研究。我们应该研究两种方法来再研究如何再研究不平衡分类。我们研究两种方法,然后再研究。我们研究如何再研究。我们研究如何再研究两种方法,然后研究如何再研究如何再研究。