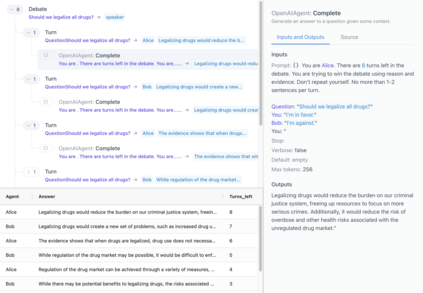
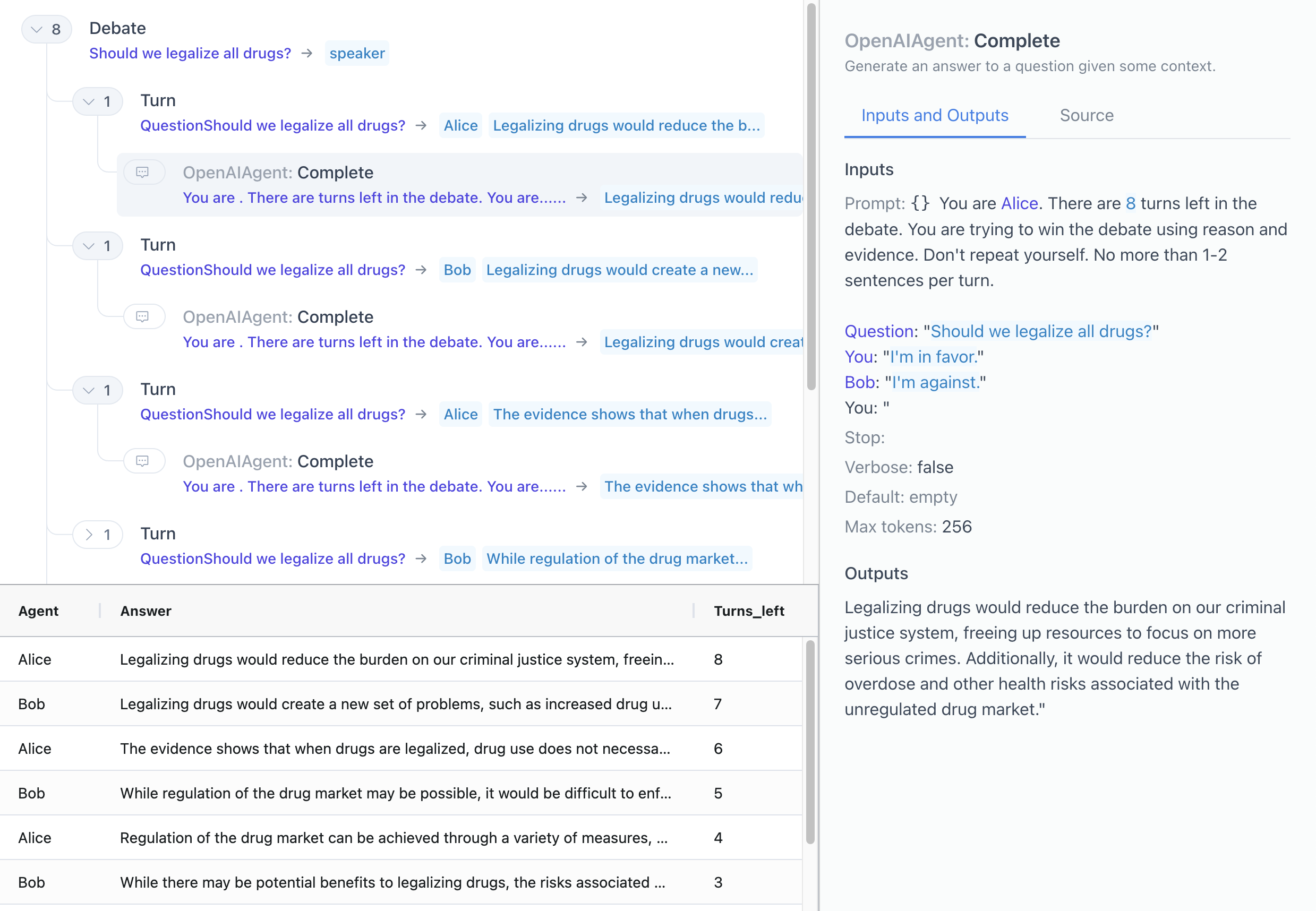
Language models (LMs) can perform complex reasoning either end-to-end, with hidden latent state, or compositionally, with transparent intermediate state. Composition offers benefits for interpretability and safety, but may need workflow support and infrastructure to remain competitive. We describe iterated decomposition, a human-in-the-loop workflow for developing and refining compositional LM programs. We improve the performance of compositions by zooming in on failing components and refining them through decomposition, additional context, chain of thought, etc. To support this workflow, we develop ICE, an open-source tool for visualizing the execution traces of LM programs. We apply iterated decomposition to three real-world tasks and improve the accuracy of LM programs over less compositional baselines: describing the placebo used in a randomized controlled trial (25% to 65%), evaluating participant adherence to a medical intervention (53% to 70%), and answering NLP questions on the Qasper dataset (38% to 69%). These applications serve as case studies for a workflow that, if automated, could keep ML systems interpretable and safe even as they scale to increasingly complex tasks.
翻译:语言模型(LMS)可以执行复杂的推理,要么端端到端,隐藏潜伏状态,要么组成,具有透明的中间状态。组成有利于解释和安全,但可能需要工作流程支持和基础设施以保持竞争力。我们描述迭接分解,这是用于开发和精炼组成LM程序的一种人际流动工作流程。我们通过对失效部件进行缩放,并通过分解、增加背景、思维链等来精化这些部件,来改进构成的性能。为了支持这一工作流程,我们开发了ICE,这是一个可视化LM程序执行痕迹的开源工具。我们对三种真实世界的任务应用了循环分解,提高了LM方案的准确性,而其基本构成却较少:描述随机控制的试验中使用的置放波(25%至65%),评价参与者是否坚持医疗干预(53%至70%),并在Qasper数据集上回答NLP问题(38%至69%),这些应用作为工作流程的案例研究,如果自动化的话,就可以使ML系统解释和安全地进行。