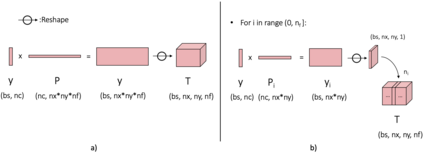
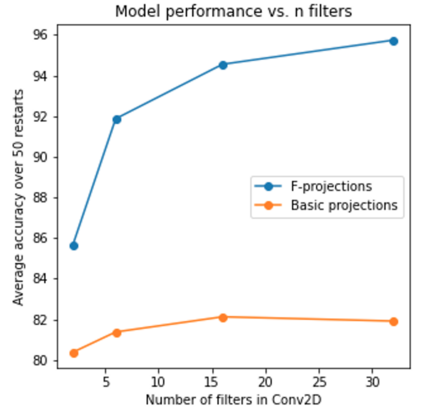
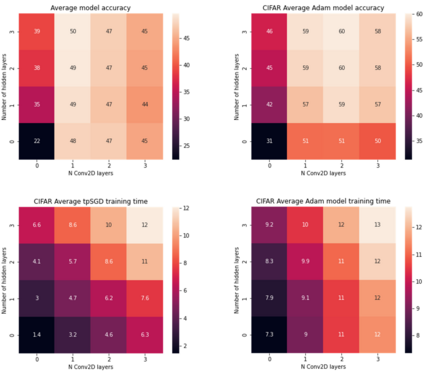
To enable learning on edge devices with fast convergence and low memory, we present a novel backpropagation-free optimization algorithm dubbed Target Projection Stochastic Gradient Descent (tpSGD). tpSGD generalizes direct random target projection to work with arbitrary loss functions and extends target projection for training recurrent neural networks (RNNs) in addition to feedforward networks. tpSGD uses layer-wise stochastic gradient descent (SGD) and local targets generated via random projections of the labels to train the network layer-by-layer with only forward passes. tpSGD doesn't require retaining gradients during optimization, greatly reducing memory allocation compared to SGD backpropagation (BP) methods that require multiple instances of the entire neural network weights, input/output, and intermediate results. Our method performs comparably to BP gradient-descent within 5% accuracy on relatively shallow networks of fully connected layers, convolutional layers, and recurrent layers. tpSGD also outperforms other state-of-the-art gradient-free algorithms in shallow models consisting of multi-layer perceptrons, convolutional neural networks (CNNs), and RNNs with competitive accuracy and less memory and time. We evaluate the performance of tpSGD in training deep neural networks (e.g. VGG) and extend the approach to multi-layer RNNs. These experiments highlight new research directions related to optimized layer-based adaptor training for domain-shift using tpSGD at the edge.
翻译:为了在快速趋同和记忆力低的边缘设备上进行学习,我们推出了一种新型的不反向调整优化算法,称为目标投影缩放梯子。tpSGD一般地将直接随机目标投射与任意丢失功能相结合,并将培训经常性神经网络(RNN)的目标投射扩大,以及进料转发网络。tpSGD使用通过随机预测标签来对网络层逐层进行仅前方传承的培训而生成的分层(SGD)和本地目标。tpSGD不需要在优化期间保留梯度,大大减少与SGD回映法(BP)方法相比的记忆分配,后者需要多种全神经网络重量、投入/输出和中间结果的事例。我们的方法比BP梯度低5%的精确度使用完全连接层、变相层和经常层的相对浅浅浅的网络。SGDFSD也比其他状态的低级和低级的低级内向级(R-R-R-R-R-R-R-R-R-R-R-R-R-R-R-R-R-R-R-le-le-le-le-valal-valal-traal-valal-valal-valal-valal-valal-valal-valal com-valal-valal-valal 的高级网络,使用低的低的低的低和低等研究和低等的低等的低的低级研究-时间性能性能模型模型,包括多级和低级和低级性能性能性能性能模型的低级性能性能性能评估。