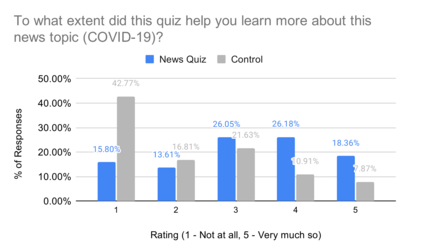
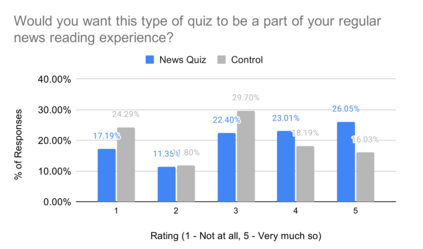
A large majority of American adults get at least some of their news from the Internet. Even though many online news products have the goal of informing their users about the news, they lack scalable and reliable tools for measuring how well they are achieving this goal, and therefore have to resort to noisy proxy metrics (e.g., click-through rates or reading time) to track their performance. As a first step towards measuring news informedness at a scale, we study the problem of quiz-style multiple-choice question generation, which may be used to survey users about their knowledge of recent news. In particular, we formulate the problem as two sequence-to-sequence tasks: question-answer generation (QAG) and distractor, or incorrect answer, generation (DG). We introduce NewsQuizQA, the first dataset intended for quiz-style question-answer generation, containing 20K human written question-answer pairs from 5K news article summaries. Using this dataset, we propose a series of novel techniques for applying large pre-trained Transformer encoder-decoder models, namely PEGASUS and T5, to the tasks of question-answer generation and distractor generation. We show that our models outperform strong baselines using both automated metrics and human raters. We provide a case study of running weekly quizzes on real-world users via the Google Surveys platform over the course of two months. We found that users generally found the automatically generated questions to be educational and enjoyable. Finally, to serve the research community, we are releasing the NewsQuizQA dataset.
翻译:大部分美国成年人至少从互联网上获得一些新闻。 尽管许多在线新闻产品的目标是让用户了解这些新闻,但他们缺乏可扩缩和可靠的工具来衡量他们实现该目标的程度,因此不得不使用噪音代理量(例如点击通速率或阅读时间)来跟踪他们的表现。作为衡量大规模新闻知情程度的第一步,我们研究了测试式多选择问题生成问题,这可以用来调查用户对最新新闻的了解。特别是,我们把问题分为两个顺序到顺序的任务:问答生成(QAG)和分流器,或错误的答案(DG)。我们介绍了用于测试式问答生成的第一个数据集(例如点击通速率或阅读时间 ) 。 作为衡量规模新闻知情程度的第一步,我们研究了测试式的多选题生成问题生成问题生成问题。我们建议了一系列新的技术,用于应用大型预先培训的变换器解码模型。 即PEGASUS和T5, 将问题分为两个序列: 社区生成问题解答器或错误的答复(DGDG ), 我们的在线数据解析器生成数据生成模型最终显示我们所找到的硬质数据生成的版本。