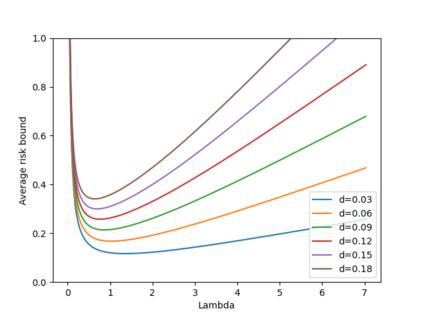
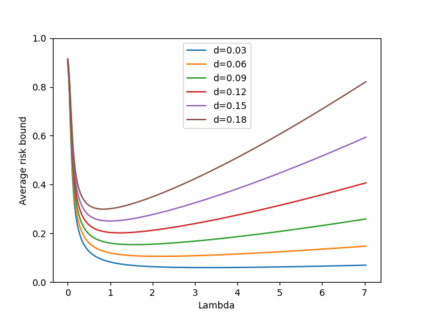
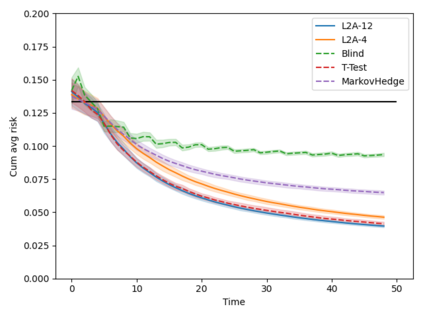
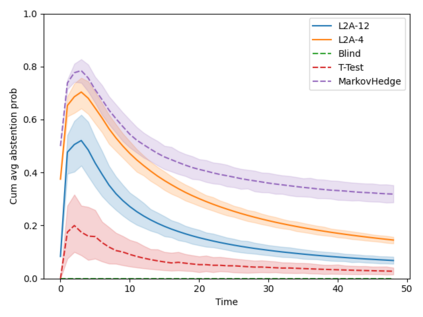
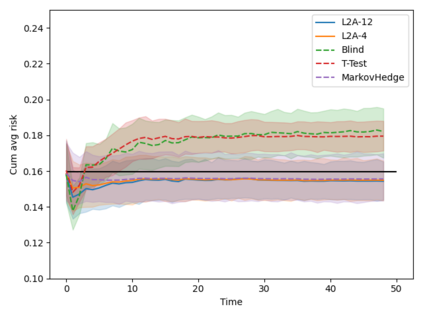
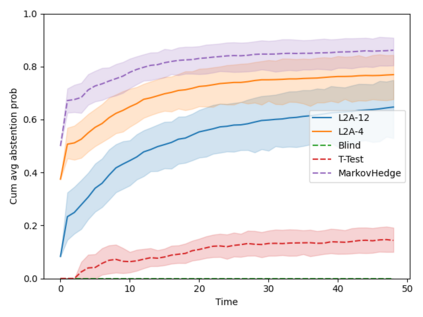
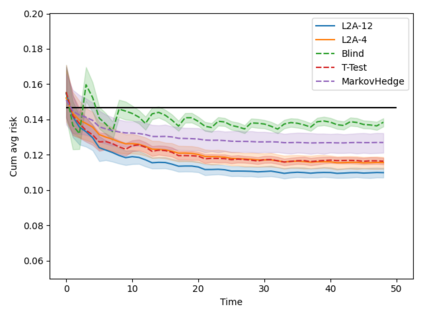
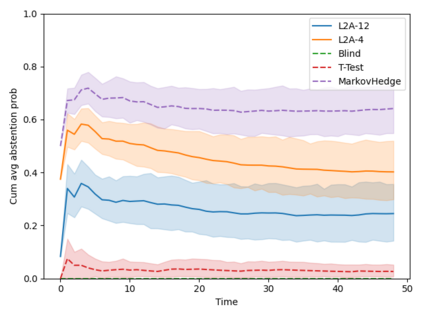
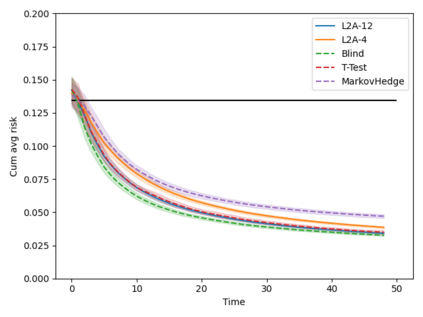
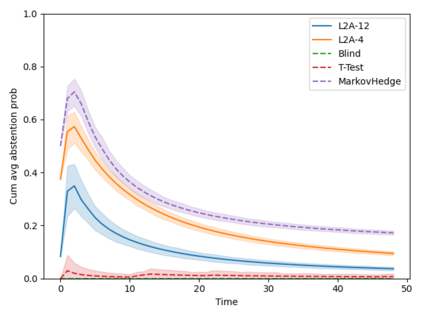
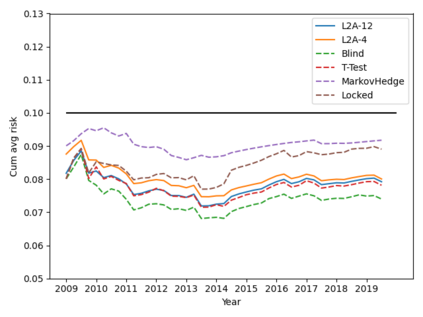
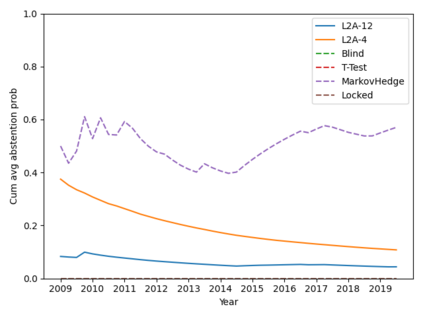
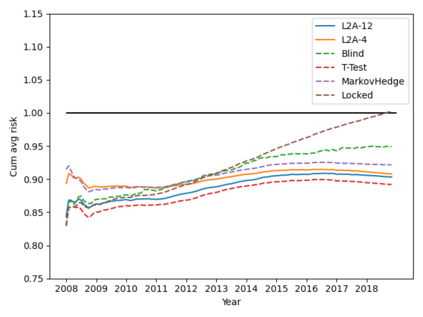
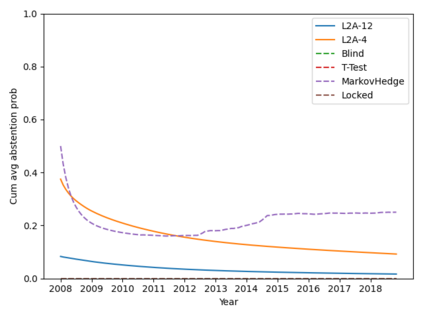
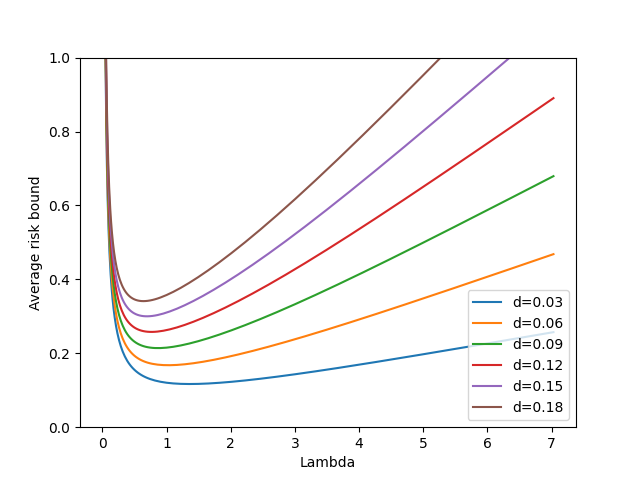
Machine learning algorithms in healthcare have the potential to continually learn from real-world data generated during healthcare delivery and adapt to dataset shifts. As such, the FDA is looking to design policies that can autonomously approve modifications to machine learning algorithms while maintaining or improving the safety and effectiveness of the deployed models. However, selecting a fixed approval strategy, a priori, can be difficult because its performance depends on the stationarity of the data and the quality of the proposed modifications. To this end, we investigate a learning-to-approve approach (L2A) that uses accumulating monitoring data to learn how to approve modifications. L2A defines a family of strategies that vary in their "optimism''---where more optimistic policies have faster approval rates---and searches over this family using an exponentially weighted average forecaster. To control the cumulative risk of the deployed model, we give L2A the option to abstain from making a prediction and incur some fixed abstention cost instead. We derive bounds on the average risk of the model deployed by L2A, assuming the distributional shifts are smooth. In simulation studies and empirical analyses, L2A tailors the level of optimism for each problem-setting: It learns to abstain when performance drops are common and approve beneficial modifications quickly when the distribution is stable.
翻译:医疗保健领域的机器学习算法有可能不断从提供医疗保健期间产生的真实世界数据中不断学习,并适应数据集的变化。因此,林业发展局正在设计能够自主批准修改机器学习算法的政策,同时保持或提高所部署模型的安全性和有效性。然而,选择固定的核准战略(先验性)可能很困难,因为其性能取决于数据的固定性能和拟议修改的质量。为此,我们调查一种学习到批准的方法(L2A),该方法利用积累的监测数据学习如何批准修改。L2A定义了一套战略,这些战略在“优化主义”和更为乐观的政策有更快的核准率的情况下,使用指数加权平均预报器对这个家庭进行搜索。为了控制所部署模型的累积风险,我们给L2A提供选择权,不做预测,而是承担一些固定的放弃成本。我们从L2A部署模型的平均风险中得出界限,假设分布变化是平坦的。在模拟研究和实验分析中,L2A裁缝是在每一个问题都学会稳定性乐观时,当它能够快速地改变时,当它能够学会稳定地进行不动的乐观时它。