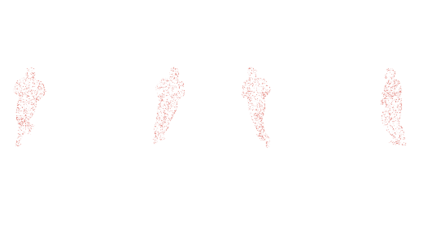We propose a new representation of human body motion which encodes a full motion in a sequence of latent motion primitives. Recently, task generic motion priors have been introduced and propose a coherent representation of human motion based on a single latent code, with encouraging results for many tasks. Extending these methods to longer motion with various duration and framerate is all but straightforward as one latent code proves inefficient to encode longer term variability. Our hypothesis is that long motions are better represented as a succession of actions than in a single block. By leveraging a sequence-to-sequence architecture, we propose a model that simultaneously learns a temporal segmentation of motion and a prior on the motion segments. To provide flexibility with temporal resolution and motion duration, our representation is continuous in time and can be queried for any timestamp. We show experimentally that our method leads to a significant improvement over state-of-the-art motion priors on a spatio-temporal completion task on sparse pointclouds. Code will be made available upon publication.
翻译:我们提出人体运动的新表述,该表述在一系列潜伏运动原始体中将一个完整的动作编码成一个序列。最近,任务性一般动议先行已经引入,并提出了基于单一潜伏代码的人类运动的一致表述,许多任务取得了令人鼓舞的结果。将这些方法扩展为具有不同持续时间和框架框架的更长期的动作,完全是直截了当的,因为一个潜伏代码证明无法有效地将较长期的变异性编码成一个代号。我们的假设是,长动作比单块的代号更能代表一系列的行动。通过利用一个顺序到顺序的结构,我们提出了一个模型,同时学习运动部分的时间分解和先行。为了提供时间分辨率和运动持续时间的灵活性,我们的代表可以连续进行时间和随时查询。我们实验性地表明,我们的方法可以大大改进在微粒点的微粒子上完成程序之前的状态运动。代码将在出版时公布。