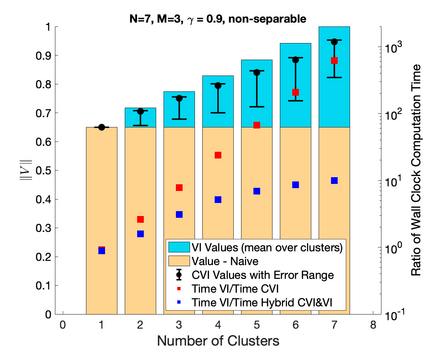
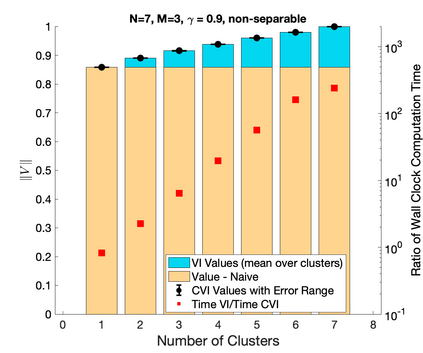
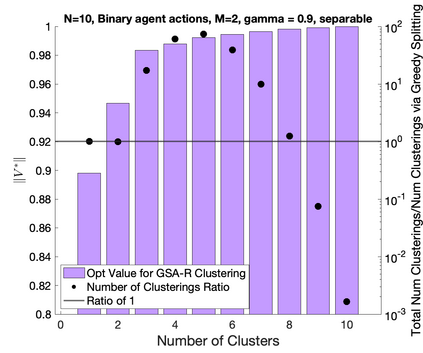
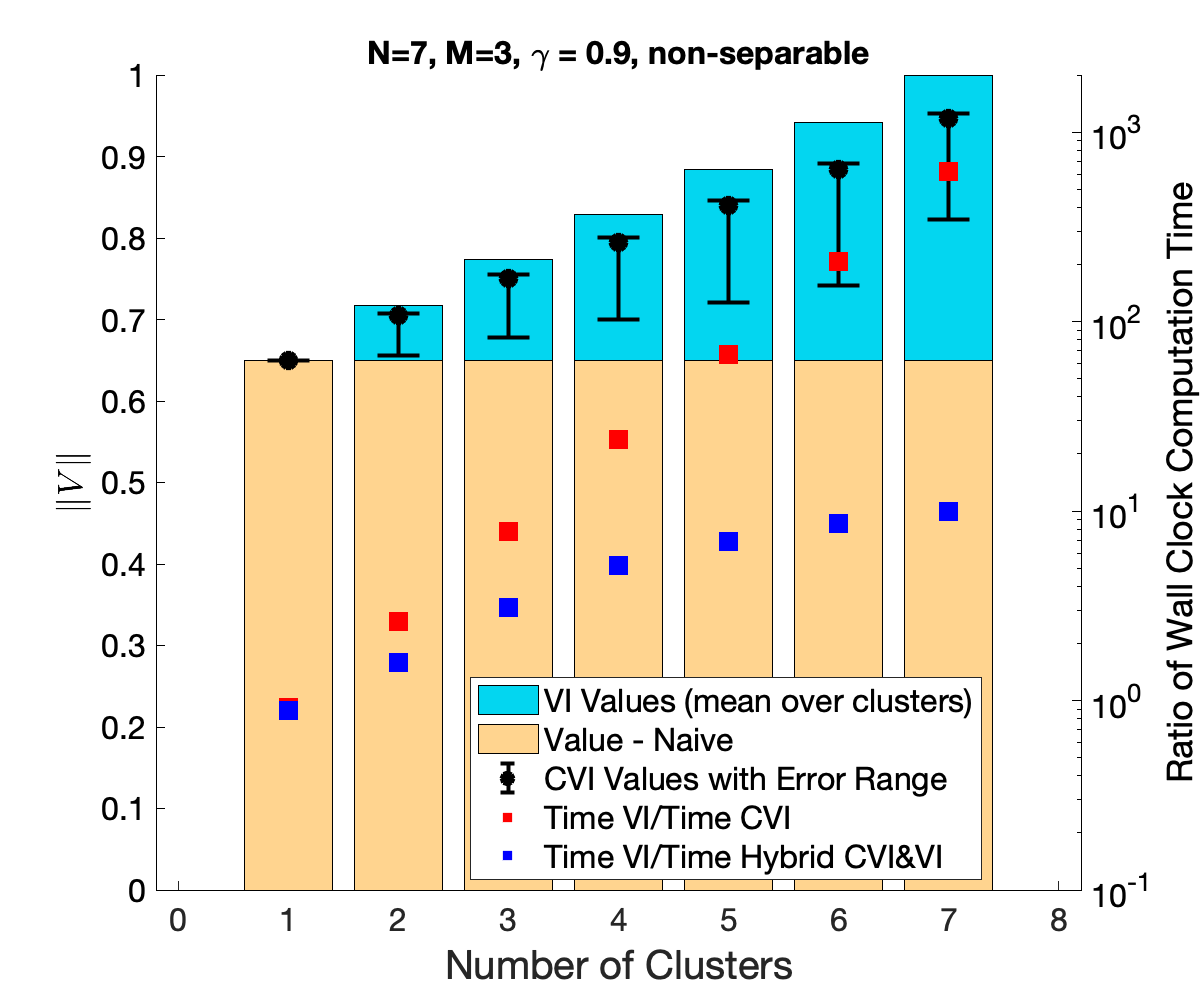
This work studies efficient solution methods for cluster-based control of transition-independent Markov decision processes (TI-MDPs). We focus on the application of control of multi-agent systems, whereby a central planner influences agents to select target joint strategies. Under mild assumptions, this can be modeled as a TI-MDP where agents are partitioned into disjoint clusters such that each cluster can receive a unique control. To efficiently find a policy in the exponentially expanded action space, we present a clustered Bellman operator that optimizes over the action space for one cluster at any evaluation. We present Clustered Value Iteration (CVI), which uses this operator to iteratively perform round robin optimization across the clusters. CVI converges exponentially faster than standard value iteration (VI), and can find policies that closely approximate the MDP's true optimal value. A special class of TI-MDPs with separable reward functions are investigated, and it is shown that CVI will find optimal policies. Finally, the optimal clustering assignment problem is explored. The value functions of separable TI-MDPs are shown to be submodular functions, and notions of submodularity are used to analyze an iterative greedy cluster splitting algorithm. The values of this clustering technique are shown to form a monotonic, submodular lower bound of the values of the optimal clustering assignment. Finally, these control ideas are demonstrated on simulated examples.
翻译:这项工作研究基于集群的控制过渡独立的Markov 决策流程(TI-MDPs)的高效解决方案方法。我们侧重于多试剂系统控制的应用,即中央规划员影响代理商选择目标联合战略。在轻度假设下,这可以建为TI-MDP,代理商被分割成不相连的集群,以便每个集群都能得到独特的控制。为了在指数扩张的行动空间中有效地找到一项政策,我们展示了一个分组的贝尔曼操作员,在任何评价中优化一个组的操作空间。我们展示了组合值透化(CVI),利用该操作员在各组之间迭接地执行圆盘优化。CVI比标准值转换(VI)快得多,并可以找到与MDP真正最佳价值相近的政策。调查了一组具有分辨性奖励功能的特殊类别,并表明CVI将找到最佳的政策。最后,探索了最佳组合分配问题。我们展示了分立的TI-MDPs的值功能,在集群各组之间反复进行轮盘优化的优化优化优化优化。 CVI的值功能被显示为次模式组合组合式组合式组合式组合式的模型模型模型,其最终分析。展示了该组合式组合式组合式组合式的模型的模型的模型的模型的模型模式的模型的模型,其结构结构结构结构结构结构结构模型被展示了。