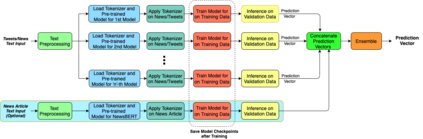
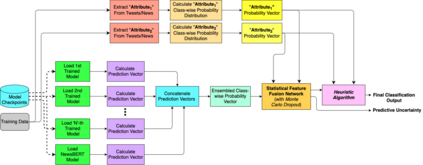
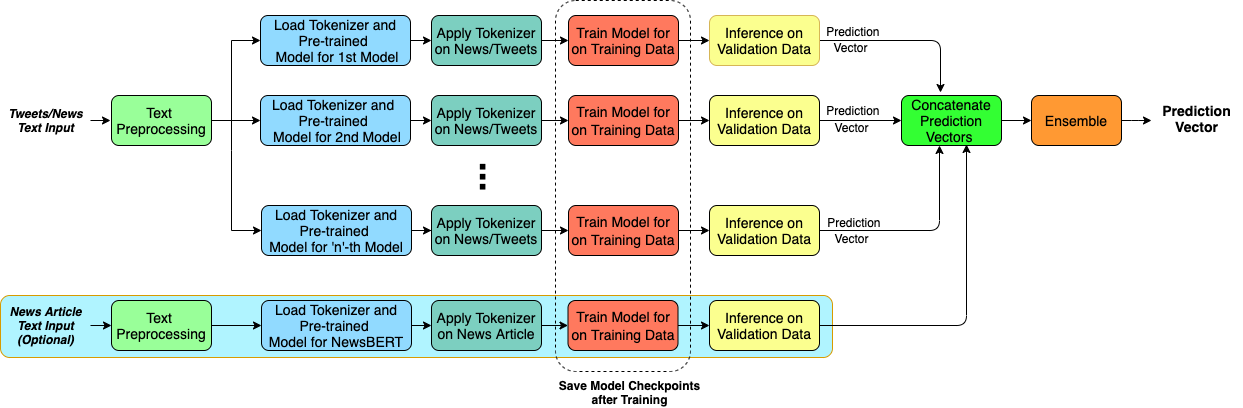
The significance of social media has increased manifold in the past few decades as it helps people from even the most remote corners of the world to stay connected. With the advent of technology, digital media has become more relevant and widely used than ever before and along with this, there has been a resurgence in the circulation of fake news and tweets that demand immediate attention. In this paper, we describe a novel Fake News Detection system that automatically identifies whether a news item is "real" or "fake", as an extension of our work in the CONSTRAINT COVID-19 Fake News Detection in English challenge. We have used an ensemble model consisting of pre-trained models followed by a statistical feature fusion network , along with a novel heuristic algorithm by incorporating various attributes present in news items or tweets like source, username handles, URL domains and authors as statistical feature. Our proposed framework have also quantified reliable predictive uncertainty along with proper class output confidence level for the classification task. We have evaluated our results on the COVID-19 Fake News dataset and FakeNewsNet dataset to show the effectiveness of the proposed algorithm on detecting fake news in short news content as well as in news articles. We obtained a best F1-score of 0.9892 on the COVID-19 dataset, and an F1-score of 0.9073 on the FakeNewsNet dataset.
翻译:在过去几十年中,社交媒体的重要性增加了,因为它帮助了世界最偏远角落的人们保持联系。随着技术的到来,数字媒体变得比以往更加相关和广泛使用。随着技术的出现,数字媒体变得比以往更加重要和广泛使用。随着技术的出现,虚假新闻和需要立即注意的推文的发行活动又重新出现。在本文中,我们描述了一个小说假新闻探测系统,它自动确定新闻项目是“真实”还是“假”,作为我们在英国挑战中的COTRAINT COVID-19 Fake News Datas 中的工作的延伸。我们使用了一个由预先训练模型组成的混合模型,随后又有一个统计特征聚合网络,加上一种新奇异的超动因算法,将新闻项目或诸如来源、用户名称处理、URL域和作者等的推文中存在的各种属性作为统计特征。我们提议的框架还量化了可靠的预测不确定性,同时为分类任务提供了适当的阶级输出信心水平。我们评估了我们在COVID-19 Fake NewsNet数据集和FakeNet数据集中的结果。我们用的是,展示了在搜索F-D-D 0.89新闻中获取的F-D数据的最佳数据作为CO1和最佳数据。