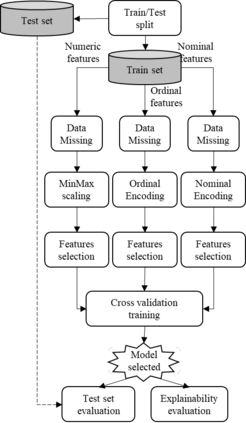
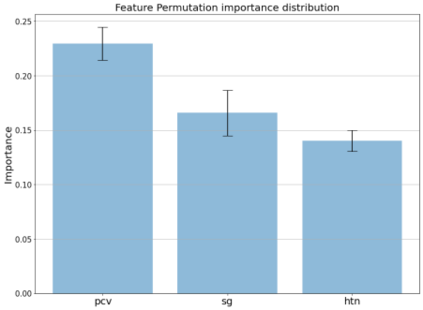
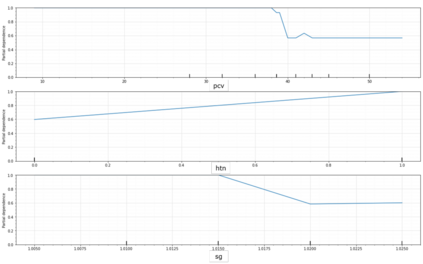
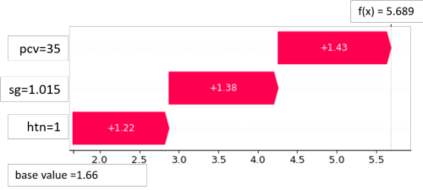
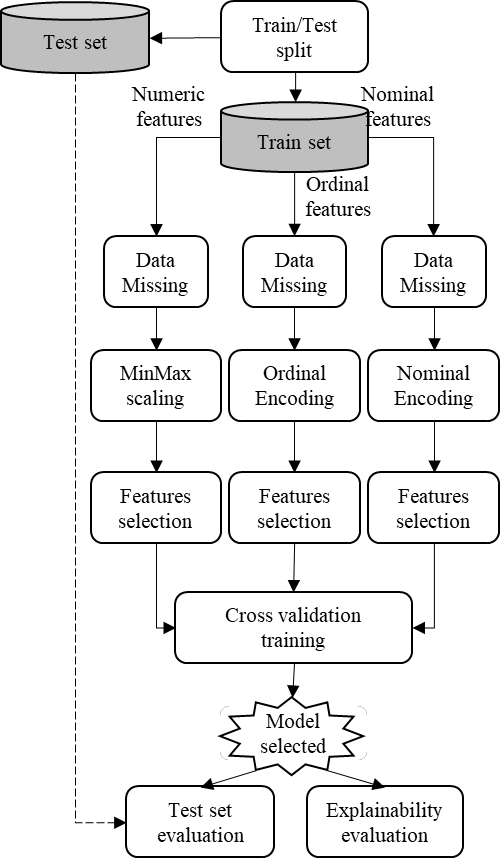
Chronic Kidney Disease (CKD), where delayed recognition implies premature mortality, is currently experiencing a globally increasing incidence and high cost to health systems. Data mining allows discovering subtle patterns in CKD indicators to contribute to an early diagnosis. This work presents the development and evaluation of an explainable prediction model that would support clinicians in the early diagnosis of CKD patients. The model development is based on a data management pipeline that detects the best combination of ensemble trees algorithms and features selected concerning classification performance. Furthermore, the main contribution of the paper involves an explainability-driven approach that allows selecting the best predictive model maintaining a balance between accuracy and explainability. Therefore, the most balanced explainable predictive model implements an extreme gradient boosting classifier over 3 features (packed cell value, specific gravity, and hypertension), achieving an accuracy of 99.2% and 97.5% with cross-validation technique and with new unseen data respectively. In addition, an analysis of the model's explainability shows that the packed cell value is the most relevant feature that influences the prediction results of the model, followed by specific gravity and hypertension. This small number of feature selected results in a reduced cost of the early diagnosis of CKD implying a promising solution for developing countries.
翻译:延迟识别意味着过早死亡的慢性肾脏疾病(CKD),延迟识别意味着过早死亡,目前正在经历一种全球范围的发病率上升和卫生系统成本高昂的慢性肾脏疾病(CKD),数据挖掘使得发现CKD指标的微妙模式有助于早期诊断;这项工作提出开发和评价一个可解释的预测模型,支持临床医生早期诊断CKD病人;模型开发的基础是一个数据管理管道,该管道检测混合树木算法和分类性能所选特征的最佳组合;此外,文件的主要贡献涉及一种解释性驱动方法,该方法能够选择保持准确性和可解释性之间的平衡的最佳预测模型。因此,最平衡的可解释性预测模型采用一种极端梯度梯度,将分类器加速到3个特征(包装细胞值、具体重力和高血压)上,从而分别实现99.2%和97.5%的精确度,与交叉校验技术和新的隐蔽数据相匹配。此外,对模型的解释表明,包装细胞价值是影响模型预测结果的最相关特征,随后是具体的重力和高压。因此,最平衡的预测性可解释性可解释性模型模型模型模型含有极小的特性,用于低的早期诊断结果。