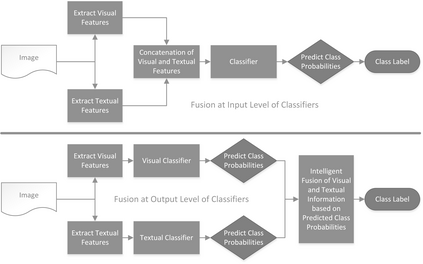
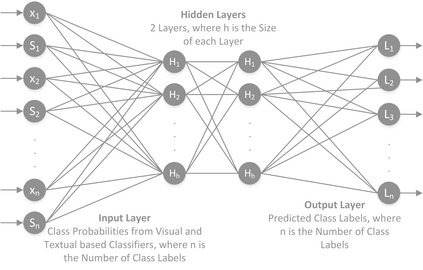
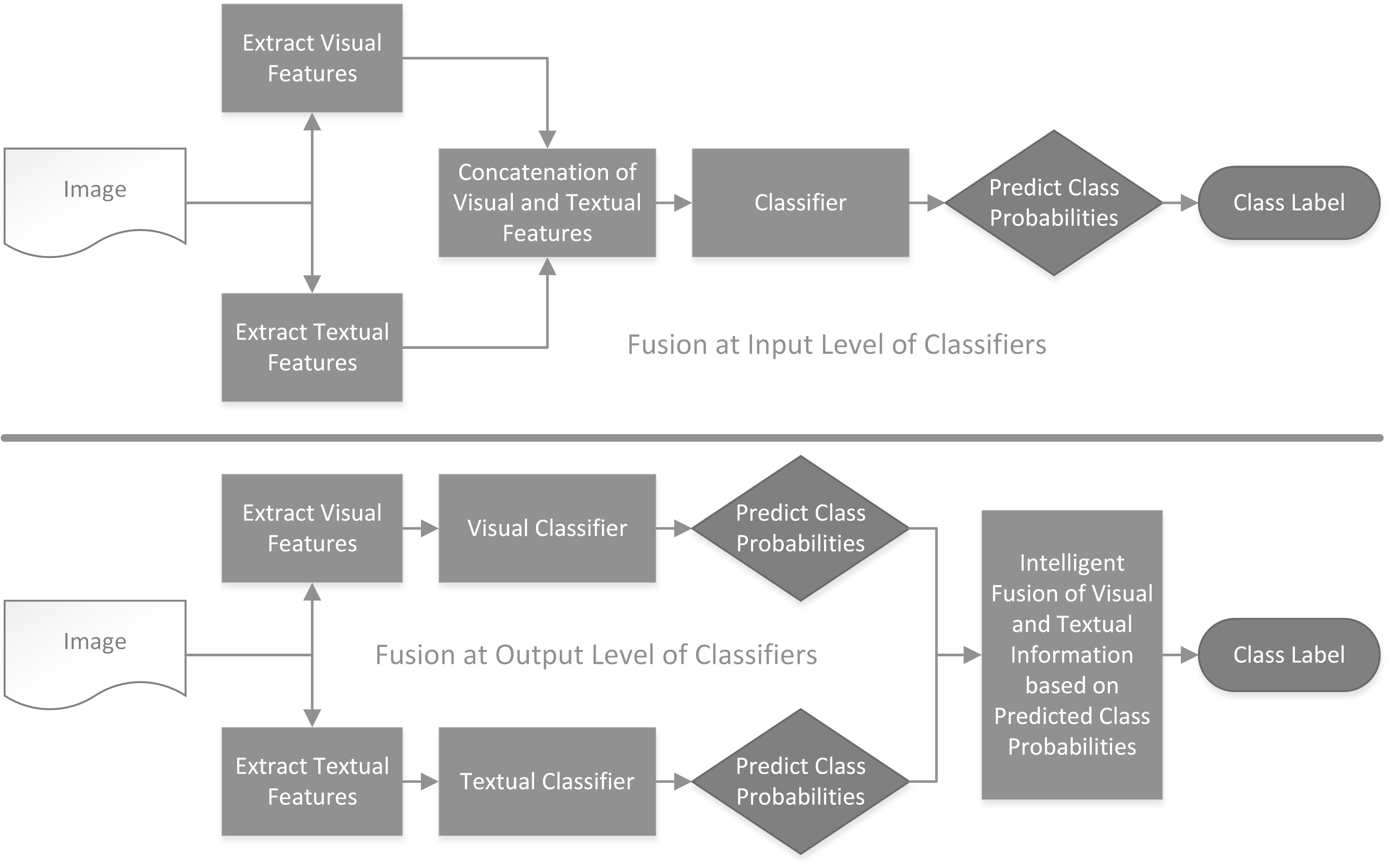
Classifiers embedded within human in the loop visual object recognition frameworks commonly utilise two sources of information: one derived directly from the imagery data of an object, and the other obtained interactively from user interactions. These computer vision frameworks exploit human high-level cognitive power to tackle particularly difficult visual object recognition tasks. In this paper, we present innovative techniques to combine the two sources of information intelligently for the purpose of improving recognition accuracy. We firstly employ standard algorithms to build two classifiers for the two sources independently, and subsequently fuse the outputs from these classifiers to make a conclusive decision. The two fusion techniques proposed are: i) a modified naive Bayes algorithm that adaptively selects an individual classifier's output or combines both to produce a definite answer, and ii) a neural network based algorithm which feeds the outputs of the two classifiers to a 4-layer feedforward network to generate a final output. We present extensive experimental results on 4 challenging visual recognition tasks to illustrate that the new intelligent techniques consistently outperform traditional approaches to fusing the two sources of information.
翻译:在环形视觉物体识别框架中嵌入人类内部的分类器通常使用两种信息来源:一种直接来自物体的图像数据,另一种通过用户互动获取。这些计算机视觉框架利用人类高层次认知能力处理特别困难的视觉物体识别任务。在本文中,我们提出创新技术,将两种信息源明智地结合起来,以提高识别准确性。我们首先使用标准算法独立地为两种来源建立两个分类器,然后将这两个分类器的输出结果结合到一个结论性决定中。提出的两种合并技术是:(一)经修改的天真贝亚算法,可适应性地选择单个分类器输出或结合两种输出,以产生明确答案;和(二)神经网络,以将两个分类器的输出输入到一个四层向前的种子网络,从而产生最终输出。我们提出了关于四个挑战性视觉识别任务的广泛实验结果,以说明新的智能技术始终超越了两种信息来源的传统配置方法。