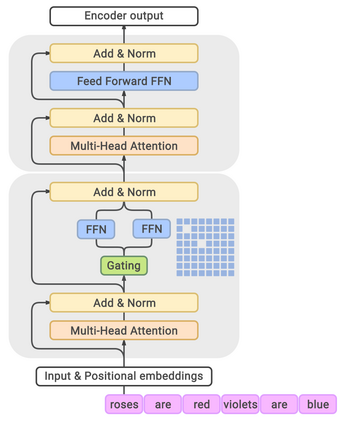
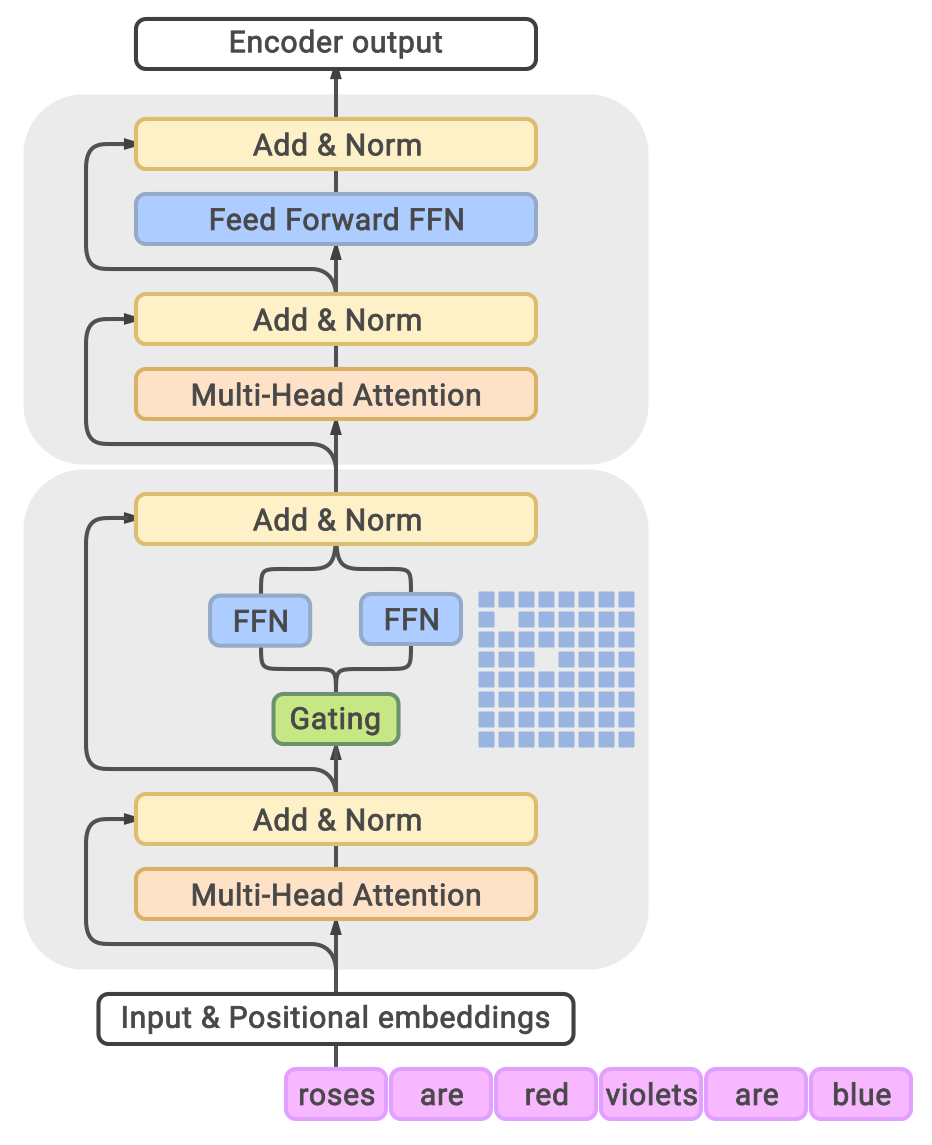
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
翻译:具有更多数据、计算和参数的扩增语言模型推动了自然语言处理的显著进展,例如,由于规模的扩大,GPT-3得以在文字内学习任务方面取得巨大成果,然而,培训这些大型密集模型需要大量的计算资源。在本文件中,我们提议并开发一个语言模型系列,名为GLAM(通用语言模型),该模型使用一种微弱的激活混合专家结构来扩大模型能力,同时与密集变异相比,培训费用也大大降低。最大的GLAM有1.2万亿参数,比GPT-3的约7x要大。它只消耗培训GPT-3的能量的三分之一,需要一半的计算浮点来进行推算,同时仍然在29项NLP任务中实现更好的总体零射和一发性能。