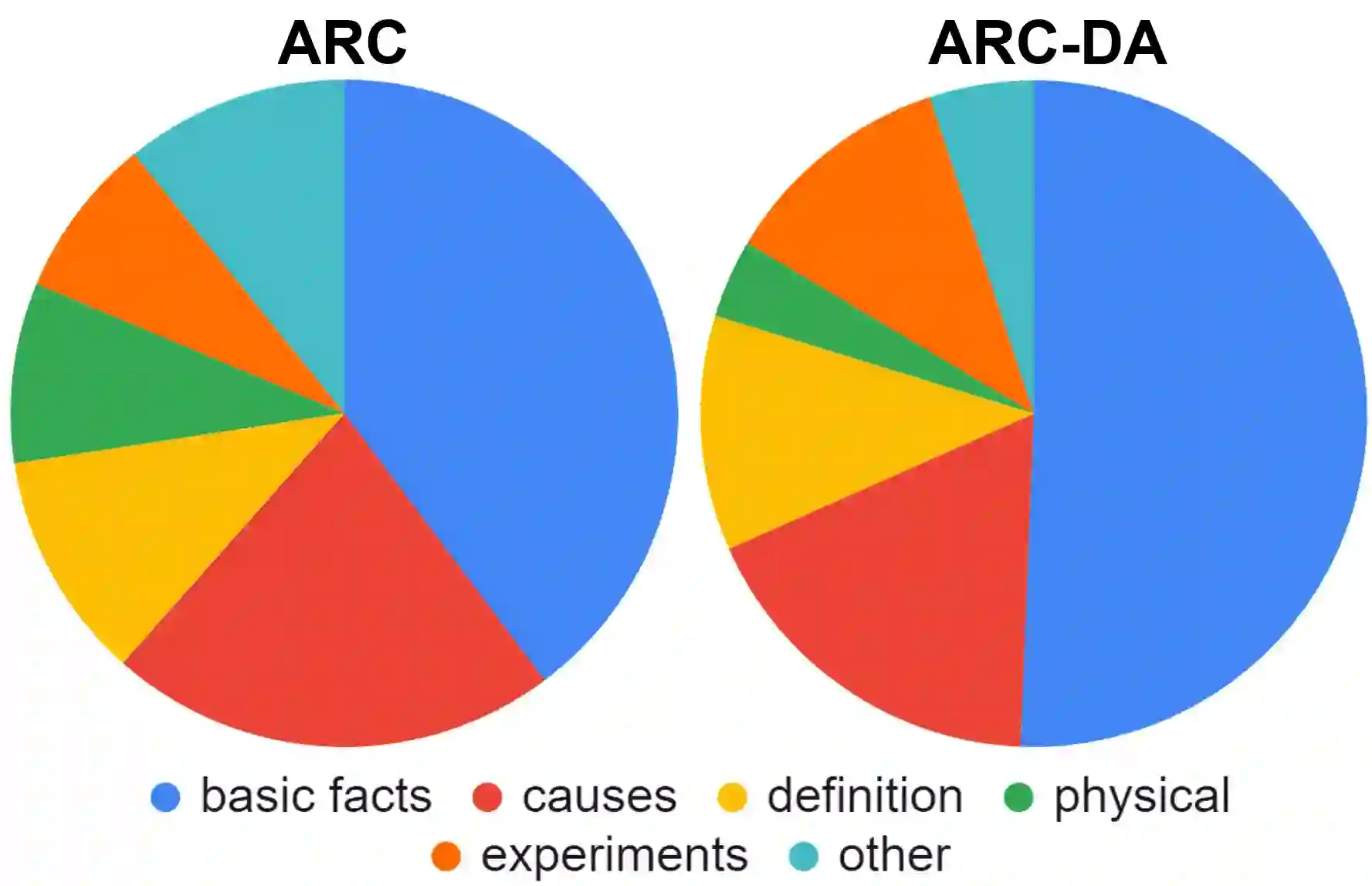
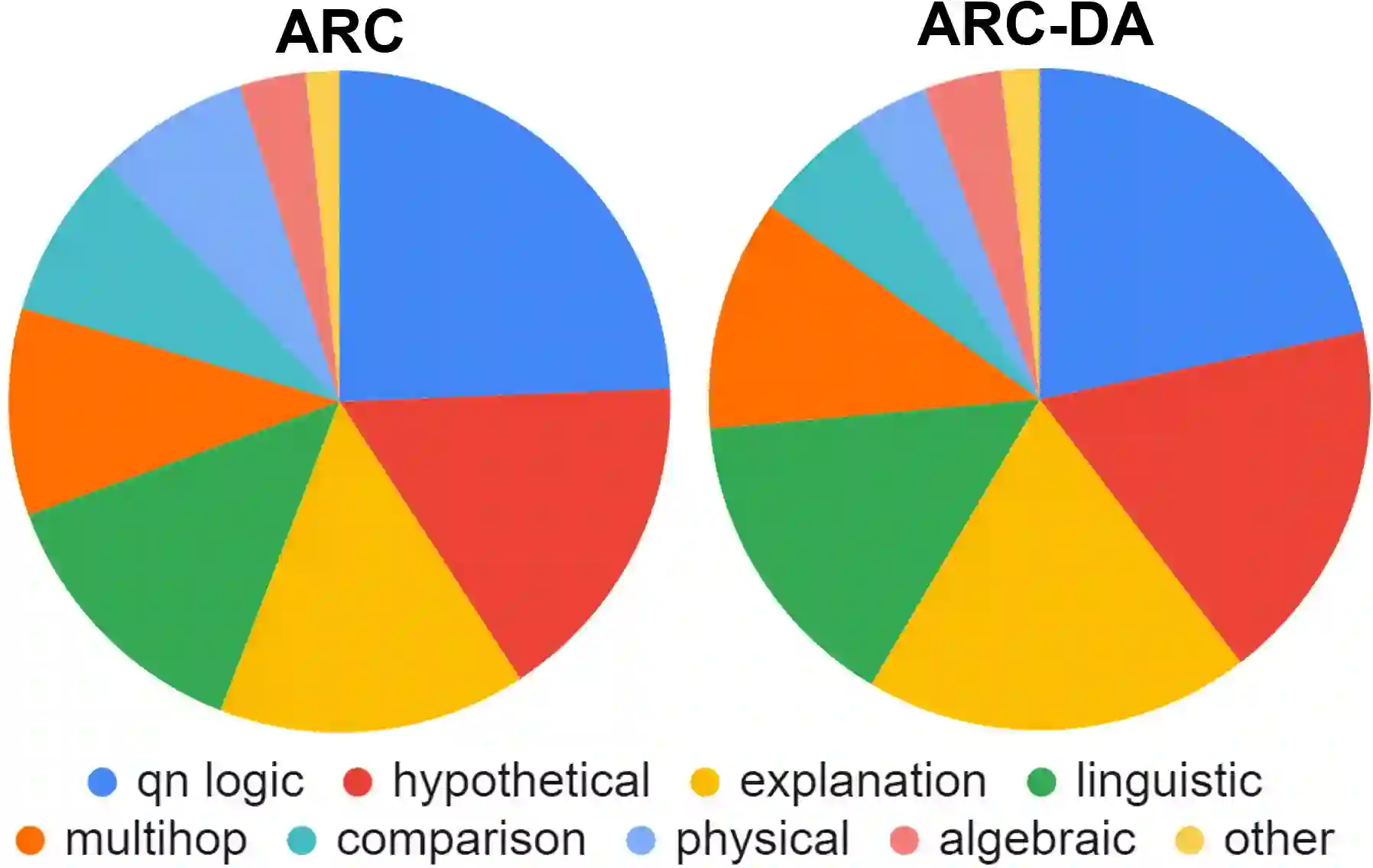
We present the ARC-DA dataset, a direct-answer ("open response", "freeform") version of the ARC (AI2 Reasoning Challenge) multiple-choice dataset. While ARC has been influential in the community, its multiple-choice format is unrepresentative of real-world questions, and multiple choice formats can be particularly susceptible to artifacts. The ARC-DA dataset addresses these concerns by converting questions to direct-answer format using a combination of crowdsourcing and expert review. The resulting dataset contains 2985 questions with a total of 8436 valid answers (questions typically have more than one valid answer). ARC-DA is one of the first DA datasets of natural questions that often require reasoning, and where appropriate question decompositions are not evident from the questions themselves. We describe the conversion approach taken, appropriate evaluation metrics, and several strong models. Although high, the best scores (81% GENIE, 61.4% F1, 63.2% ROUGE-L) still leave considerable room for improvement. In addition, the dataset provides a natural setting for new research on explanation, as many questions require reasoning to construct answers. We hope the dataset spurs further advances in complex question-answering by the community. ARC-DA is available at https://allenai.org/data/arc-da
翻译:我们展示了ARC-DA数据集,这是ARC(AI2 解释挑战)多选择数据集的直接回答(“公开回答”、“freeform”)版本的多选择数据集。虽然ARC在社区中具有影响力,但其多选择格式并不代表现实世界问题,而且多种选择格式可能特别易受文物的影响。ARC-DA数据集通过将问题转换为直接回答格式,同时结合众包和专家审查,解决了这些关切。由此产生的数据集包含2985个问题,共8436个有效答案(问题通常不止一个有效的答案)。ARC-DA是第一个DA数据集,其中自然问题往往需要推理,而适当的问题分解形式本身并不明显。我们描述了采用的转换方法、适当的评价指标和几个强型模型。尽管得分很高(81% GENIE,61.4 % F1, 63.2% ROUGE-L),但仍有相当大的改进余地。此外,数据集为新的研究提供了自然背景,因为许多问题都需要推理,因此需要用RAC/ADA的复杂数据解答。我们希望,因此可以推理算出MA-DA/DA。