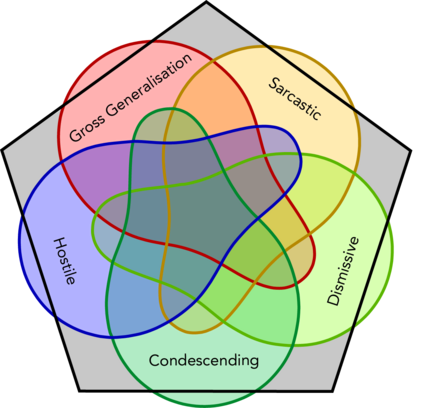
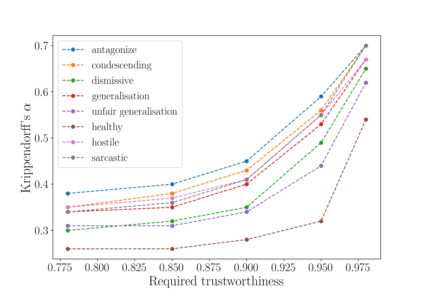
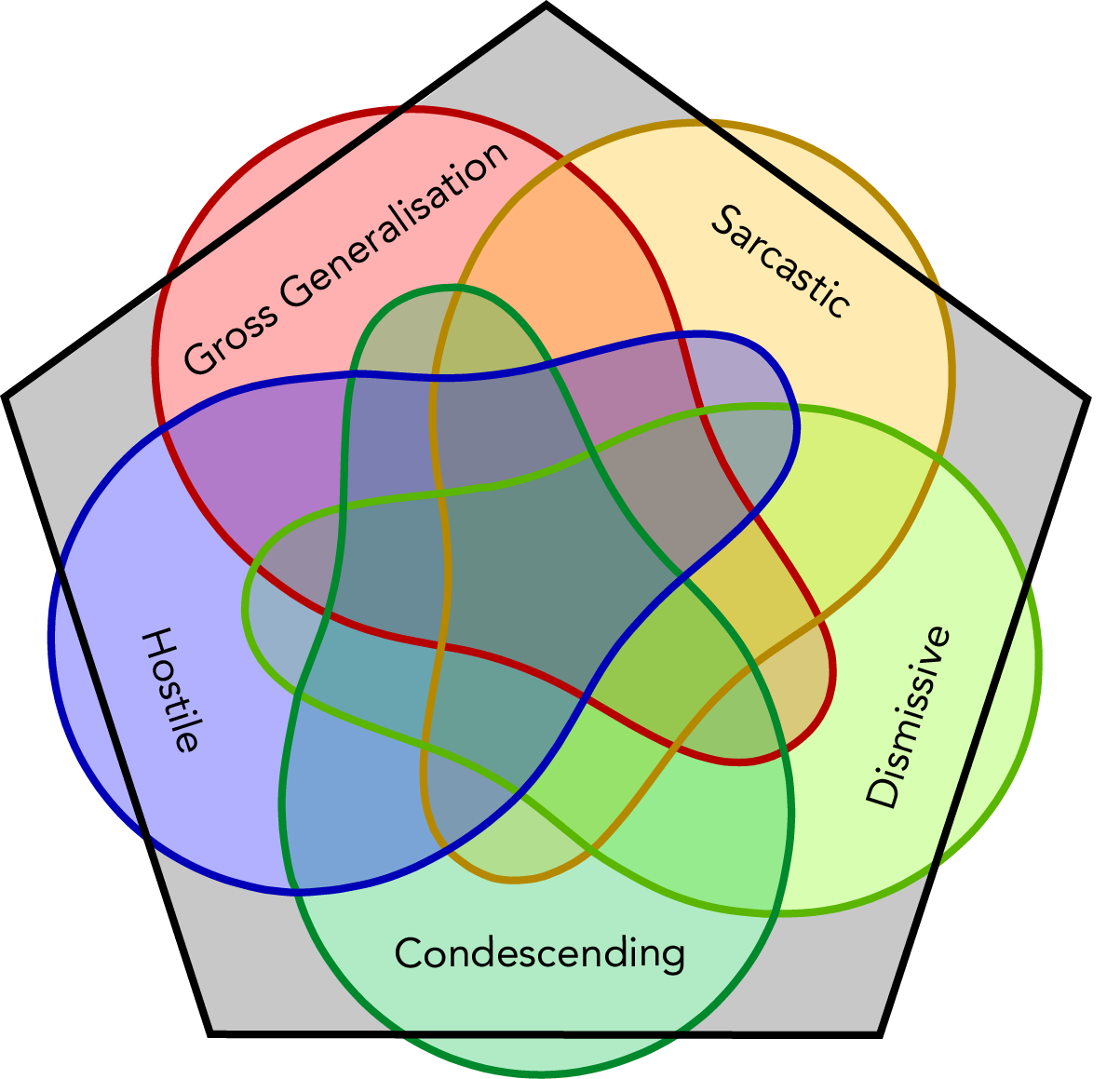
We present a new dataset of approximately 44000 comments labeled by crowdworkers. Each comment is labelled as either 'healthy' or 'unhealthy', in addition to binary labels for the presence of six potentially 'unhealthy' sub-attributes: (1) hostile; (2) antagonistic, insulting, provocative or trolling; (3) dismissive; (4) condescending or patronising; (5) sarcastic; and/or (6) an unfair generalisation. Each label also has an associated confidence score. We argue that there is a need for datasets which enable research based on a broad notion of 'unhealthy online conversation'. We build this typology to encompass a substantial proportion of the individual comments which contribute to unhealthy online conversation. For some of these attributes, this is the first publicly available dataset of this scale. We explore the quality of the dataset, present some summary statistics and initial models to illustrate the utility of this data, and highlight limitations and directions for further research.
翻译:我们提出了一个由人群工人标注的大约44,000条评论组成的新数据集。 每条评论都标为“健康”或“不健康 ”, 除了六种潜在“不健康”子属性的二进制标签:(1) 敌对;(2) 敌对、侮辱、挑衅或牵引;(3) 鄙视;(4) 任人唯亲或赞助;(5) 讽刺;和/或(6) 不公平的概括。 每条标签都有相关的信任分。 我们认为,需要数据集,使基于“不健康在线对话”的广泛概念的研究成为可能。 我们构建了这种分类,以包括大量有助于不健康在线对话的个人评论。 对于其中一些属性,这是这一规模的第一个可公开获取的数据集。 我们探索数据集的质量, 提供一些简要统计数据和初步模型来说明这些数据的效用, 并强调进一步研究的局限性和方向。