用 TensorFlow hub 在 Keras 中做 ELMo 嵌入

本文为 AI 研习社编译的技术博客,原标题 :
Elmo Embeddings in Keras with TensorFlow hub
作者 | Jacob Zweig
翻译 | 胡瑛皓 编辑 | 酱番梨、王立鱼
原文链接:
https://towardsdatascience.com/elmo-embeddings-in-keras-with-tensorflow-hub-7eb6f0145440
注:本文的相关链接请访问文末【阅读原文】
最新发布的Tensorflow hub提供了一个接口,方便使用现有模型进行迁移学习。我们有时用Keras快速构建模型原型,这里只要少许改几个地方就能将Keras与Tensorflow hub提供的模型整合!
TensorFlow Hub预训练模型中有一个由Allen NLP开发的ELMo嵌入模型。ELMo嵌入是基于一个bi-LSTM内部状态训练而成,用以表示输入文本的上下文特征。ELMo嵌入在很多NLP任务中的表现均超越了GloVe和Word2Vec嵌入的效果。
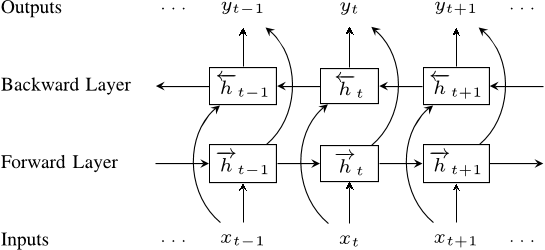
上面的bi-LSTM采用大型语料训练而成,其内部特征被结合在一起,最后得到对于输入文本的具有丰富表达且上下文敏感的特征。
这里是Strong Analytics团队的一些代码,他们用Keras构建了一个基于最先进的ELMo嵌入的NLP模型原型。
首先加载一些数据:
# Load all files from a directory in a DataFrame.def load_directory_data(directory):data = {}data["sentence"] = []data["sentiment"] = []for file_path in os.listdir(directory):with tf.gfile.GFile(os.path.join(directory, file_path), "r") as f:data["sentence"].append(f.read())data["sentiment"].append(re.match("\d+_(\d+)\.txt", file_path).group(1))return pd.DataFrame.from_dict(data)# Merge positive and negative examples, add a polarity column and shuffle.def load_dataset(directory):pos_df = load_directory_data(os.path.join(directory, "pos"))neg_df = load_directory_data(os.path.join(directory, "neg"))pos_df["polarity"] = 1neg_df["polarity"] = 0return pd.concat([pos_df, neg_df]).sample(frac=1).reset_index(drop=True)# Download and process the dataset files.def download_and_load_datasets(force_download=False):dataset = tf.keras.utils.get_file(fname="aclImdb.tar.gz",origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",extract=True)train_df = load_dataset(os.path.join(os.path.dirname(dataset),"aclImdb", "train"))test_df = load_dataset(os.path.join(os.path.dirname(dataset),"aclImdb", "test"))return train_df, test_df# Reduce logging output.tf.logging.set_verbosity(tf.logging.ERROR)train_df, test_df = download_and_load_datasets()train_df.head()
接下来处理这些数据。注意此处使用字符串作为Keras模型的输入,创建一个numpy对象数组。考虑到内存情况,数据只取前150单词 (ELMo嵌入需要消耗大量计算资源,最好使用GPU)。
# Create datasets (Only take up to 150 words)train_text = train_df['sentence'].tolist()train_text = [' '.join(t.split()[0:150]) for t in train_text]train_text = np.array(train_text, dtype=object)[:, np.newaxis]train_label = train_df['polarity'].tolist()test_text = test_df['sentence'].tolist()test_text = [' '.join(t.split()[0:150]) for t in test_text]test_text = np.array(test_text, dtype=object)[:, np.newaxis]test_label = test_df['polarity'].tolist()
在Keras中实例化ELMo嵌入需要自建一个层,并确保嵌入权重可训练:
class ElmoEmbeddingLayer(Layer):def __init__(self, **kwargs):self.dimensions = 1024self.trainable = Truesuper(ElmoEmbeddingLayer, self).__init__(**kwargs)def build(self, input_shape):self.elmo = hub.Module('https://tfhub.dev/google/elmo/2', trainable=self.trainable, name="{}_module".format(self.name))self.trainable_weights += K.tf.trainable_variables(scope="^{}_module/.*".format(self.name))super(ElmoEmbeddingLayer, self).build(input_shape)def call(self, x, mask=None):result = self.elmo(K.squeeze(K.cast(x, tf.string), axis=1),as_dict=True,signature='default',)['default']return resultdef compute_mask(self, inputs, mask=None):return K.not_equal(inputs, '--PAD--')def compute_output_shape(self, input_shape):return (input_shape[0], self.dimensions)
现在就可以用ElmoEmbeddingLayer构建并训练自己的模型了:
input_text = layers.Input(shape=(1,), dtype=tf.string)embedding = ElmoEmbeddingLayer()(input_text)dense = layers.Dense(256, activation='relu')(embedding)pred = layers.Dense(1, activation='sigmoid')(dense)model = Model(inputs=[input_text], outputs=pred)model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])model.summary()model.fit(train_text,train_label,validation_data=(test_text, test_label),epochs=5,batch_size=32)
方法就是这样! Tensorflow hub上有很多模型,可以多拿这些模型来试试!
本文的IPython笔记地址:
https://github.com/strongio/keras-elmo/blob/master/Elmo%20Keras.ipynb
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1597








