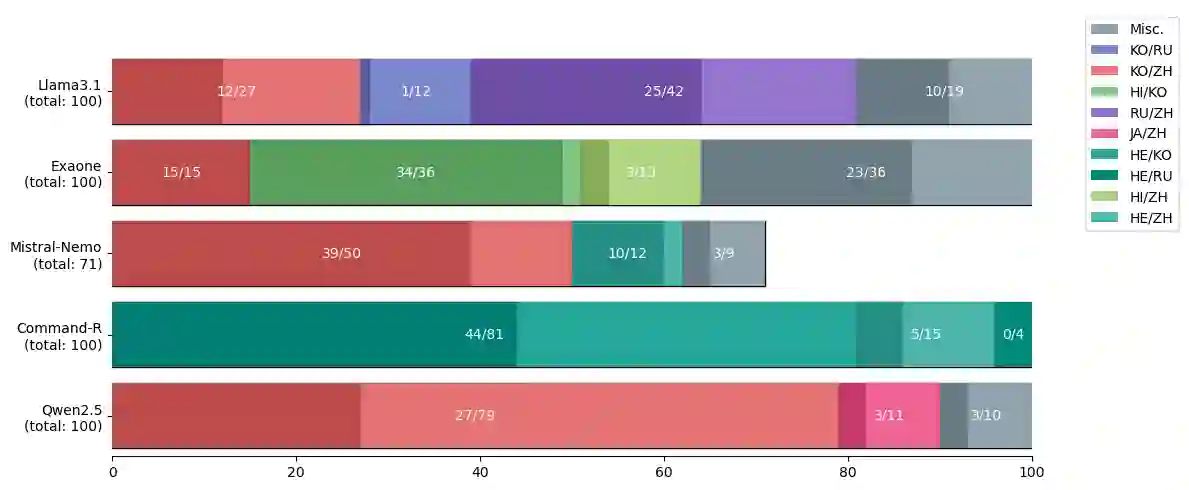
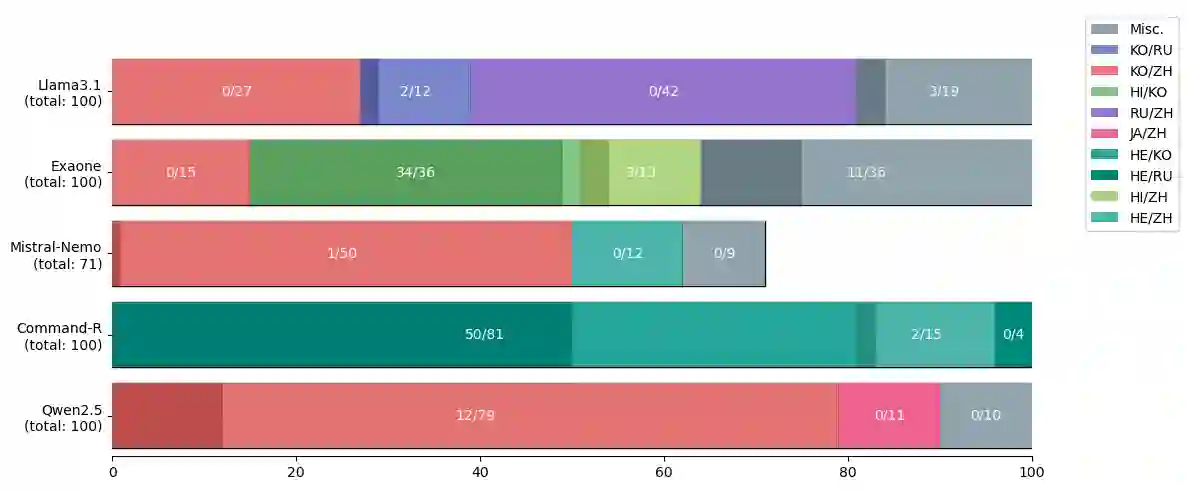
Tokenization is a crucial step that bridges human-readable text with model-readable discrete tokens. However, recent studies have revealed that tokenizers can be exploited to elicit unwanted model behaviors. In this work, we investigate incomplete tokens, i.e., undecodable tokens with stray bytes resulting from byte-level byte-pair encoding (BPE) tokenization. We hypothesize that such tokens are heavily reliant on their adjacent tokens and are fragile when paired with unfamiliar tokens. To demonstrate this vulnerability, we introduce improbable bigrams: out-of-distribution combinations of incomplete tokens designed to exploit their dependency. Our experiments show that improbable bigrams are significantly prone to hallucinatory behaviors. Surprisingly, the same phrases have drastically lower rates of hallucination (90% reduction in Llama3.1) when an alternative tokenization is used. We caution against the potential vulnerabilities introduced by byte-level BPE tokenizers, which may introduce blind spots to language models.
翻译:分词是将人类可读文本转换为模型可读离散词元的关键步骤。然而,近期研究表明,分词器可能被利用以诱发模型的不良行为。本文研究不完整词元,即由字节级字节对编码分词产生的、包含游离字节的不可解码词元。我们假设此类词元高度依赖其相邻词元,在与陌生词元配对时极为脆弱。为证明这一脆弱性,我们引入不可能二元组:即利用不完整词元依赖性而设计的、分布外的不完整词元组合。实验表明,不可能二元组极易引发幻觉行为。值得注意的是,当采用替代分词方案时,相同短语的幻觉率大幅降低(在Llama3.1中降低90%)。我们警示字节级BPE分词器可能引入的潜在脆弱性,这或将为语言模型带来盲区。