大型语言模型(LLMs)通过将自然语言描述直接转化为可执行代码,从根本上重塑了自动化软件开发,并推动了 GitHub Copilot(微软)、Cursor(Anysphere)、Trae(字节跳跳)和 Claude Code(Anthropic)等工具的商业化应用。该领域已从早期的规则系统显著演进至基于 Transformer 的架构,在 HumanEval 等基准测试中的成功率从个位数跃升至超过 95%。 本文提供了一项关于代码大语言模型(Code LLMs)的全面综述与实践指南,通过一系列分析性和探针实验,系统性地考察了模型从数据构建到后训练的完整生命周期,涵盖先进提示范式、代码预训练、监督微调、强化学习以及自主编程智能体等关键环节。我们深入分析了通用大语言模型(如 GPT-4、Claude、LLaMA)与专用于代码的大模型(如 StarCoder、Code LLaMA、DeepSeek-Coder 和 QwenCoder)的编程能力,对其核心技术、架构设计决策及权衡取舍进行了批判性评估。 此外,我们阐明了学术研究(如基准测试与任务设计)与工业部署(如实际软件开发中的代码任务)之间的研究—实践鸿沟,涵盖代码正确性、安全性、对大型代码库的上下文感知能力,以及与开发工作流的集成等关键挑战,并将前沿研究方向与实际应用需求进行映射。 最后,我们开展了一系列实验,对代码预训练、监督微调和强化学习进行了全面分析,内容覆盖扩展律(scaling law)、框架选型、超参数敏感性、模型架构设计以及数据集对比等多个维度。
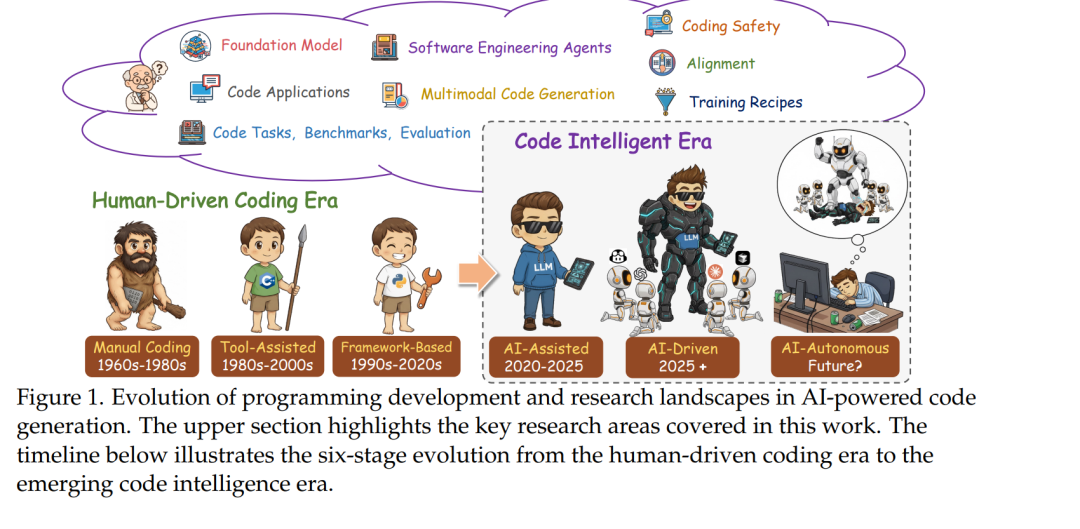
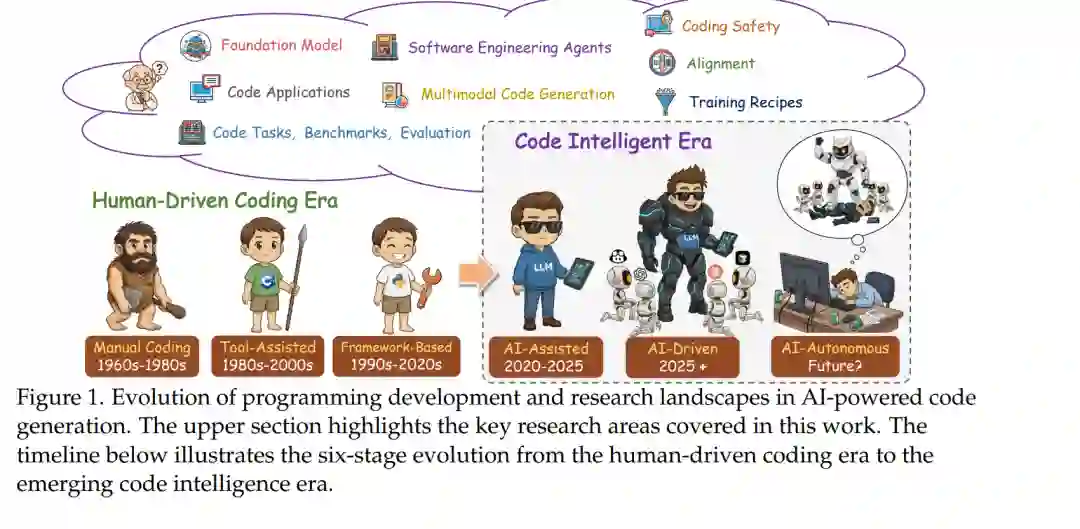
- 引言
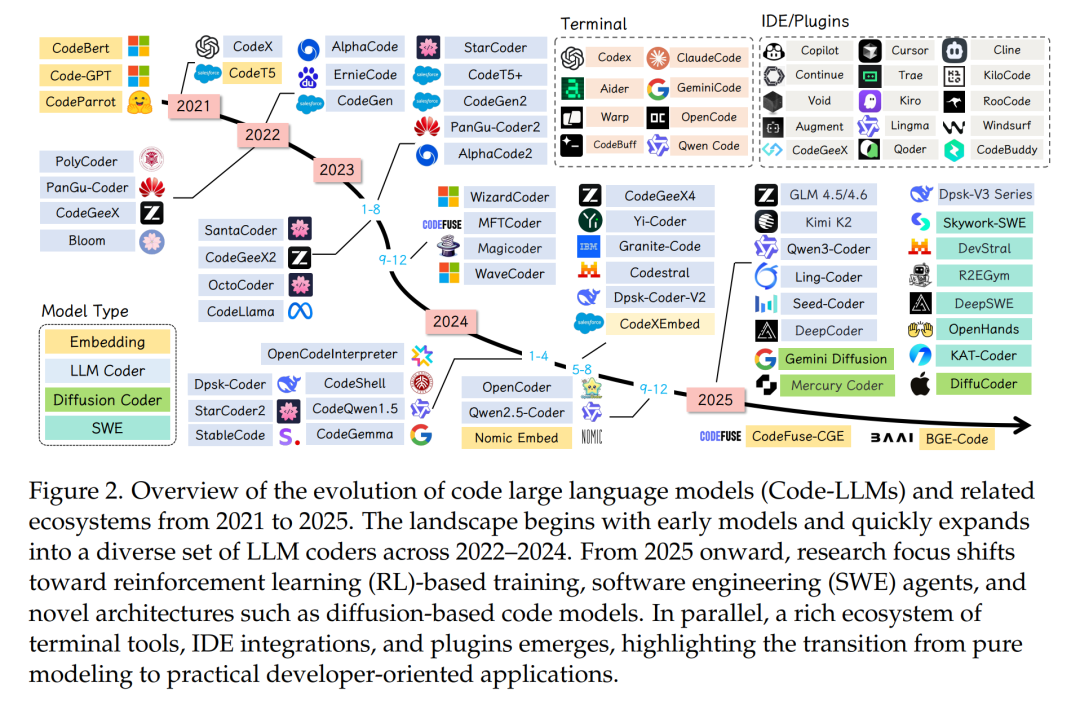
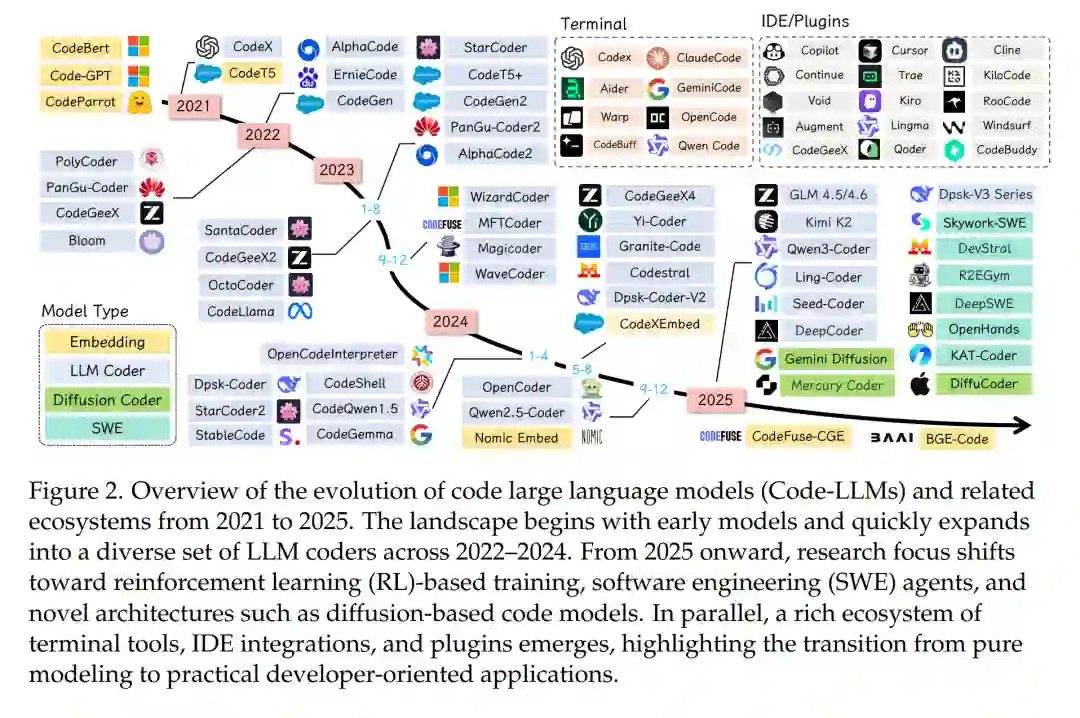
大型语言模型(Large Language Models, LLMs)[66, 67, 192, 424, 435, 750, 753, 755, 756] 的兴起推动了自动化软件开发的范式变革,从根本上重构了人类意图与可执行代码之间的关系 [1306]。现代 LLM 在各类代码相关任务中展现出卓越能力,包括代码补全 [98]、代码翻译 [1158]、代码修复 [619, 970] 以及代码生成 [139, 161]。这些模型有效地将多年积累的编程专业知识提炼为易于使用的、可遵循指令的工具,使不同技能水平的开发者均可利用来自 GitHub、Stack Overflow 及其他代码相关网站的数据进行开发。 在 LLM 所支持的各类任务中,代码生成尤为具有变革性——它能够将自然语言描述直接转化为功能完备的源代码,从而消解了领域知识与技术实现之间的传统壁垒。这一能力已超越学术探索阶段,通过一系列商业与开源工具转化为现实生产力,包括:(1) GitHub Copilot(微软)[321],在集成开发环境中提供智能代码补全;(2) Cursor(Anysphere)[68],一款以 AI 为核心的代码编辑器,支持对话式编程;(3) CodeGeeX(智谱 AI)[24],支持多语言代码生成;(4) CodeWhisperer(亚马逊)[50],与 AWS 服务深度集成;(5) Claude Code(Anthropic)[194] 与 Gemini CLI(Google)[335],均为命令行工具,允许开发者直接在终端中将编码任务委托给 Claude 或 Gemini [67, 955],以支持智能体驱动的编程工作流。这些应用不仅重塑了软件开发流程,也挑战了关于编程生产力的传统假设,并重新定义了人类创造力与机器辅助之间的边界。 如图 1 所示,代码生成技术的发展轨迹呈现出一条清晰的技术成熟与范式演进路径。早期方法受限于启发式规则与基于概率语法的框架 [42, 203, 451],其本质脆弱——仅适用于狭窄领域,难以泛化至丰富多样的编程场景。基于 Transformer 的架构 [291, 361] 的出现并非简单的性能提升,而是一次对问题空间的根本性重构,通过注意力机制 [997] 与模型规模,精准捕捉自然语言意图与代码结构之间的复杂关联。尤为引人注目的是,这些模型展现出的指令跟随能力并非显式编程或直接优化的结果,表明将高层目标转化为可执行实现的能力,可能是大规模学习丰富表征的自然产物。这种“编程民主化”[138, 864]——使非专家用户也能通过自然语言生成复杂程序——对 21 世纪的劳动力发展、创新节奏乃至计算素养的本质均具有深远影响 [223, 904]。 当前代码 LLM 领域呈现出通用模型与专用模型并行发展的战略分化,各具优势与权衡。以 GPT [747, 750, 753]、Claude [66, 67, 192] 和 LLaMA [690, 691, 979, 980] 系列为代表的通用大模型,通过融合海量自然语言与代码语料,建立起对上下文、意图和领域知识的细腻理解;而 StarCoder [563]、Code LLaMA [859]、DeepSeek-Coder [232]、CodeGemma [1295] 与 QwenCoder [435, 825] 等专用代码模型,则通过对编程中心化数据的聚焦预训练与任务导向的架构优化,在代码专项基准测试中取得更优性能。在 HumanEval [161] 等标准化基准上,模型成功率从个位数跃升至 95% 以上,既体现了算法创新,也反映了对代码本质更深层次的理解。尽管代码具有高度形式化特征,但其在组合语义与上下文依赖等方面与自然语言存在共性。 尽管学术研究活跃且商业化进程迅速,当前文献仍存在创新广度与系统性分析深度之间的显著鸿沟。现有综述多采用全景式视角,或涵盖广泛的代码任务类别,或聚焦于早期模型,未能充分整合最新进展。尤其缺乏深入探讨的是前沿系统所采用的复杂数据构建策略——如何在数据规模与质量之间取得平衡,以及如何通过指令微调使模型行为与开发者意图对齐。此类对齐技术包括:引入人类反馈以优化输出、采用高级提示范式(如思维链推理 [chain-of-thought] 与少样本学习)、构建具备多步问题分解能力的自主编程智能体、采用检索增强生成(Retrieval-Augmented Generation, RAG)方法将输出锚定于权威参考,以及开发超越简单二元正确性、评估代码质量、效率与可维护性的新型评测框架。 如图 2 所示,Kimi-K2 [957]、GLM-4.5/4.6 [25, 1248]、Qwen3Coder [825]、Kimi-Dev [1204]、Claude [67]、Deepseek-V3.2-Exp [234] 与 GPT-5 [753] 等最新 LLM 正是上述创新的集大成者,但其贡献仍散见于各类独立发表的研究,缺乏系统整合。表 1 对比了多篇关于代码智能或 LLM 的综述,从八个维度进行评估:领域范围、是否聚焦代码、是否使用 LLM、预训练、监督微调(Supervised Fine-Tuning, SFT)、强化学习(Reinforcement Learning, RL)、代码 LLM 的训练方案(Training Recipes)以及应用场景。这些综述覆盖了通用代码生成、基于生成式 AI(GenAI)的软件工程、代码摘要和基于 LLM 的智能体等多个方向。尽管多数综述关注代码及其应用,但在技术细节覆盖上差异显著:部分涉及 LLM 与预训练,但极少涵盖强化学习方法。 本文旨在对面向代码智能的大型语言模型研究进行全面且前沿的整合,系统考察模型全生命周期,涵盖从初始数据构建与指令微调,到高级代码应用及自主编程智能体开发的关键阶段。为提供从代码基础模型到智能体与应用的全面且实用的研究指南,我们构建了一个连接理论基础与现代代码生成系统实现的详细框架(如表 1 所示)。本文的主要贡献包括:
- 统一分类体系:提出当代代码 LLM 的统一分类法,追溯其从早期基于 Transformer 的模型演进至最新一代具备涌现推理能力的指令微调系统的完整脉络;
- 全流程技术剖析:系统分析从数据构建与预处理策略、预训练目标与架构创新,到高级微调方法(包括监督指令微调与强化学习)的完整技术管道;
- 前沿范式解析:深入探讨定义当前性能上限的关键范式,包括提示技术(如思维链 [1174])、检索增强生成方法,以及能够执行复杂多步问题求解的自主编程智能体;
- 评测体系批判性评估:全面评述现有基准测试与评估方法,讨论其优势与局限,并聚焦于从“功能正确性”向“代码质量、可维护性与效率”等多维评估的演进挑战;
- 趋势与挑战综合研判:整合 GPT-5、Claude 4.5 等最新突破性模型的洞见,识别将塑造下一代代码生成系统的关键趋势与开放问题;
- 实验验证与分析:开展大规模实验,从扩展律(scaling laws)、框架选型、超参数敏感性、模型架构及数据集对比等多个维度,对代码预训练、监督微调与强化学习进行系统性实证研究。
本综述旨在为初入该领域的研究者提供全面参考,同时为希望在生产环境中部署相关技术的从业者提供战略路线图。