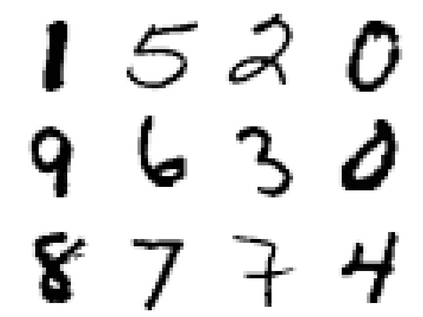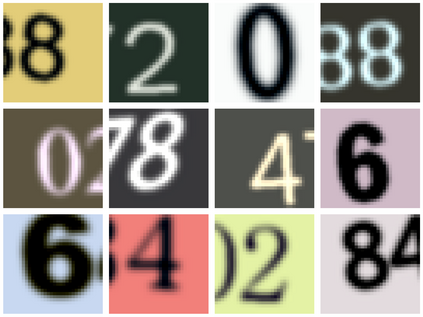In practice, and more especially when training deep neural networks, visual recognition rules are often learned based on various sources of information. On the other hand, the recent deployment of facial recognition systems with uneven predictive performances on different population segments highlights the representativeness issues possibly induced by a naive aggregation of image datasets. Indeed, sampling bias does not vanish simply by considering larger datasets, and ignoring its impact may completely jeopardize the generalization capacity of the learned prediction rules. In this paper, we show how biasing models, originally introduced for nonparametric estimation in (Gill et al., 1988), and recently revisited from the perspective of statistical learning theory in (Laforgue and Cl\'emen\c{c}on, 2019), can be applied to remedy these problems in the context of visual recognition. Based on the (approximate) knowledge of the biasing mechanisms at work, our approach consists in reweighting the observations, so as to form a nearly debiased estimator of the target distribution. One key condition for our method to be theoretically valid is that the supports of the distributions generating the biased datasets at disposal must overlap, and cover the support of the target distribution. In order to meet this requirement in practice, we propose to use a low dimensional image representation, shared across the image databases. Finally, we provide numerical experiments highlighting the relevance of our approach whenever the biasing functions are appropriately chosen.
翻译:在实践中,特别是当培训深层神经网络时,视觉识别规则往往在各种信息来源的基础上学习。另一方面,最近在不同人口部分部署面部识别系统,其预测性表现不均,这凸显了图像数据集天真汇总可能引起的代表性问题。 事实上,抽样偏差不会简单地通过考虑更大的数据集而消失,而忽视其影响,这完全可能危及所学的预测规则的普及能力。在本文件中,我们展示了最初在(Gill等人,1988年)为非参数估算引入的偏差模型,以及最近从统计学习理论(Laforgue和Cl\'emen\c{c}2019年)中(Laforge and Cl\'emen\c{c})角度重新审视的偏差识别系统如何在视觉识别背景下可以用来纠正这些问题。根据(大概)对工作偏差机制的了解,我们的方法包括重新权衡观察结果,从而形成对目标分布的偏差估测度。我们方法的一个重要条件就是理论上有效的一个条件,即每当我们提出偏差的分布时,在处置时,我们提出的图象的分布必须能够适当地支持在最后的顺序上提供我们提出的图象分布。