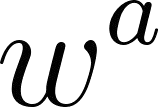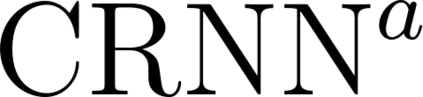Music transcription, which deals with the conversion of music sources into a structured digital format, is a key problem for Music Information Retrieval (MIR). When addressing this challenge in computational terms, the MIR community follows two lines of research: music documents, which is the case of Optical Music Recognition (OMR), or audio recordings, which is the case of Automatic Music Transcription (AMT). The different nature of the aforementioned input data has conditioned these fields to develop modality-specific frameworks. However, their recent definition in terms of sequence labeling tasks leads to a common output representation, which enables research on a combined paradigm. In this respect, multimodal image and audio music transcription comprises the challenge of effectively combining the information conveyed by image and audio modalities. In this work, we explore this question at a late-fusion level: we study four combination approaches in order to merge, for the first time, the hypotheses regarding end-to-end OMR and AMT systems in a lattice-based search space. The results obtained for a series of performance scenarios -- in which the corresponding single-modality models yield different error rates -- showed interesting benefits of these approaches. In addition, two of the four strategies considered significantly improve the corresponding unimodal standard recognition frameworks.
翻译:音乐转录处理将音乐源转换成结构化的数字格式,是音乐信息检索系统(MIR)的一个关键问题。在解决计算学术语的这一挑战时,MIR社区遵循两条研究线:音乐文件,即光学音乐识别(OMR),或录音,即自动音乐传输(AMT),上述输入数据的不同性质决定了这些领域制定具体模式框架。然而,它们最近对顺序标签任务的定义导致一个共同产出代表制,从而可以对一个综合模式进行研究。在这方面,多式图像和音频音乐转录包括将图像和音频模式传递的信息有效结合的挑战。在这项工作中,我们探索了这个问题的延迟融合层面:我们研究四种组合方法,以便首次将终端到终端的OMR和AMT系统的假设合并到一个基于固定空间的搜索空间。为一系列绩效假设方案 -- -- 其中对应的单一模式模型产生不同的误差率率。我们研究了这四种方法的有意义的程度。