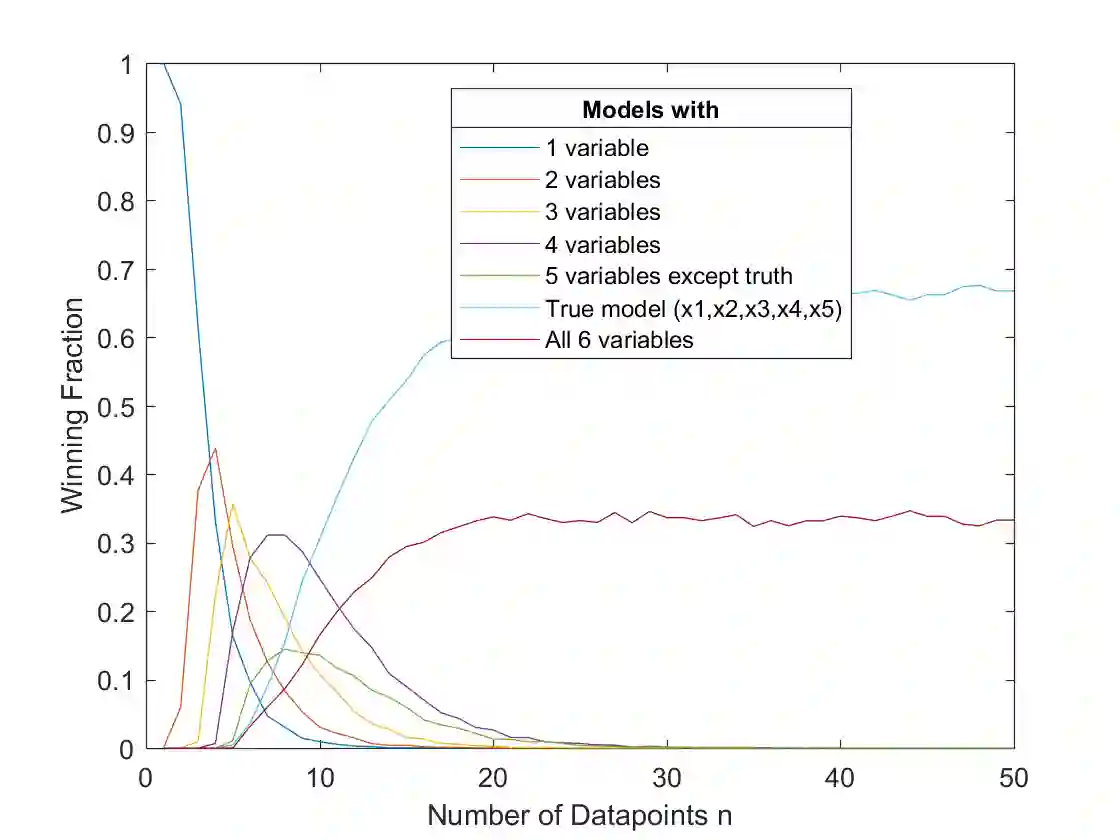
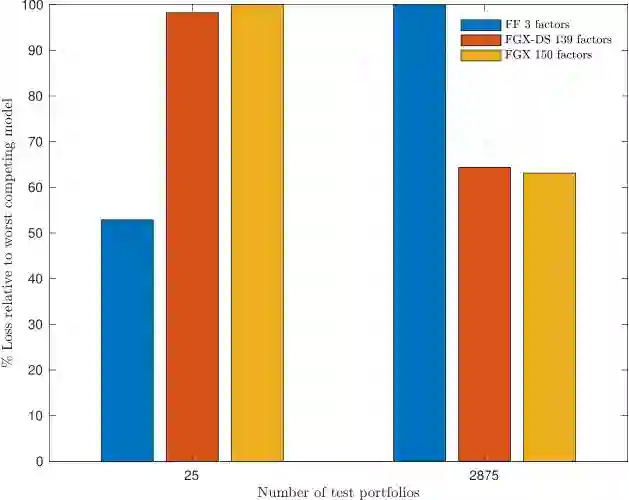
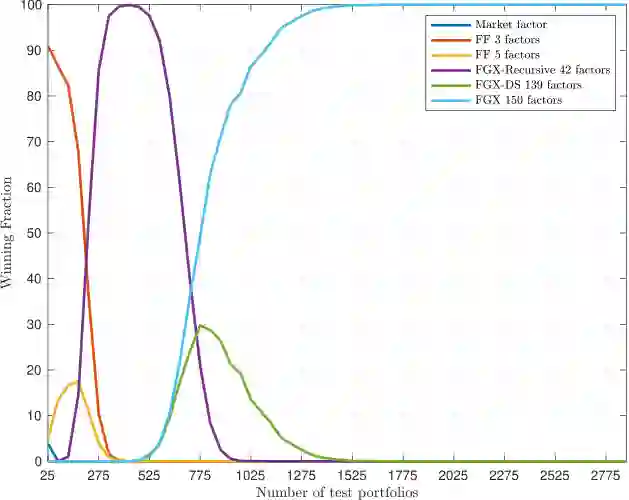
Different agents need to make a prediction. They observe identical data, but have different models: they predict using different explanatory variables. We study which agent believes they have the best predictive ability -- as measured by the smallest subjective posterior mean squared prediction error -- and show how it depends on the sample size. With small samples, we present results suggesting it is an agent using a low-dimensional model. With large samples, it is generally an agent with a high-dimensional model, possibly including irrelevant variables, but never excluding relevant ones. We apply our results to characterize the winning model in an auction of productive assets, to argue that entrepreneurs and investors with simple models will be over-represented in new sectors, and to understand the proliferation of "factors" that explain the cross-sectional variation of expected stock returns in the asset-pricing literature.
翻译:不同的代理商需要做出预测。 他们观察相同的数据, 但有不同的模型: 他们预测使用不同的解释变量。 我们研究哪个代理商认为他们拥有最好的预测能力 -- 以最小的主观后端平均平方预测错误来衡量 -- 并显示它如何取决于样本大小。 有了小样本, 我们给出的结果显示它是一个使用低维模型的代理商。 有大样本, 它一般是一个高维模型的代理商, 可能包括无关的变量, 但从不排斥相关变量。 我们运用我们的结果来在生产性资产拍卖中描述胜出模型的特点, 论证拥有简单模型的企业家和投资者在新部门中的比例会过高, 并理解“ 因素” 的扩散, 解释资产定价文献中预期股票回报的跨部门变化。