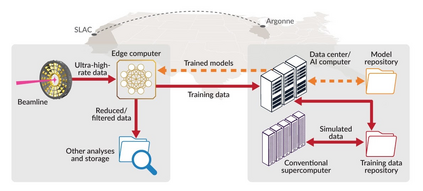
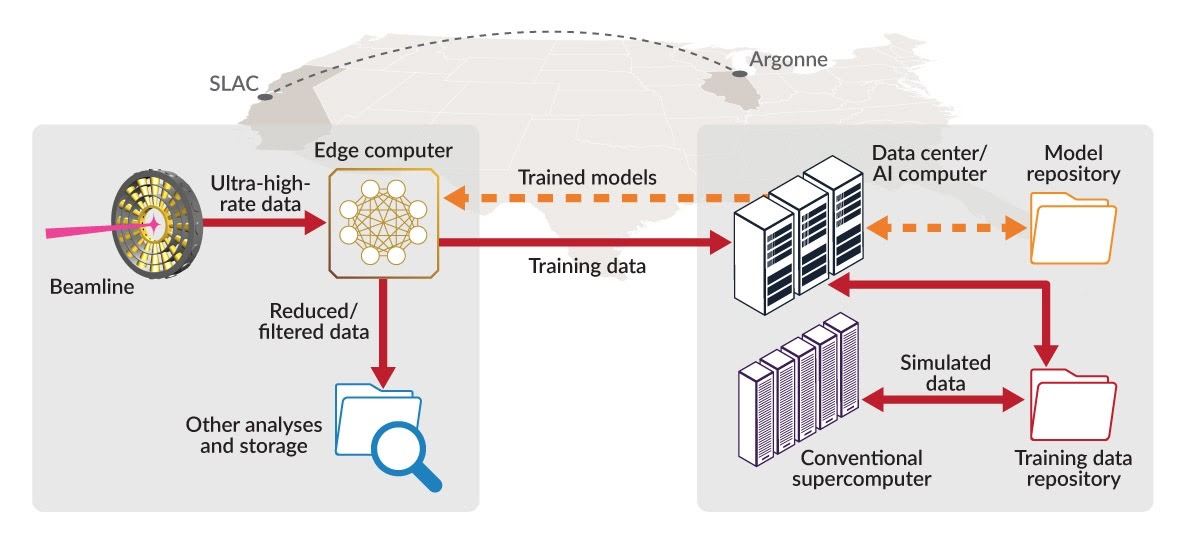
Extremely high data rates at modern synchrotron and X-ray free-electron lasers (XFELs) light source beamlines motivate the use of machine learning methods for data reduction, feature detection, and other purposes. Regardless of the application, the basic concept is the same: data collected in early stages of an experiment, data from past similar experiments, and/or data simulated for the upcoming experiment are used to train machine learning models that, in effect, learn specific characteristics of those data; these models are then used to process subsequent data more efficiently than would general-purpose models that lack knowledge of the specific dataset or data class. Thus, a key challenge is to be able to train models with sufficient rapidity that they can be deployed and used within useful timescales. We describe here how specialized data center AI systems can be used for this purpose.
翻译:现代同步器和X射线自由电子激光光源光束极高的数据率激励使用机器学习方法减少数据、特征探测和其他目的。 不论应用如何,基本概念是一样的:在试验早期阶段收集的数据、过去类似实验中的数据和(或)为即将进行的实验模拟的数据,都用于培训机器学习模型,这些模型实际上学习了这些数据的具体特点;这些模型随后被用来处理数据的效率高于缺乏对具体数据集或数据类别知识的普通用途模型。因此,一项关键的挑战是如何能够以足够快的速度培训模型,使其能够在有用的时间尺度内部署和使用。 我们在这里说明如何为此目的使用专门的数据中心AI系统。